아래 내용은 GMIG( Genomic Medicine Interest Group ) 2회 모임 후 관련 내용을 멤버들과 share한 내용으로, 내용의 변경 없이 그대로 여기에 남깁니다.
-------------------------------------------------------------------------------------
2회 모임의 내용 중에 제(금창원)가 지적하고 싶었던 내용이 하나더 있는데, 그것은 바로 IT에 대한 '환상'의 경계 입니다. 박재범 대표님의 발표를 보면서 그런 생각이 들었는데, 재범 대표님의 발표에서 중요하게 받아들여야 할 것은 IT의 영역 중 '소비자 중심의 UX / UI 와 관련한 부분'들로 BT에 적용되지 않았던 '일반 대중'을 대상으로 접근성이 높고, 지속가능한 유용성을 꾸준히 제공하는 IT application이 필요하다는 점 이라고 봅니다.
이런 부분은 인류 역사상 BT에 거의 접목이 된 적이 없는 부분에 가깝다 봅니다. 근접하는 성공으로 한국인 정세주 대표가 뉴욕에서 창업한 Noom의 다이어트앱 정도를 들 수 있을 것 같습니다. ( 최초엔 running trajectory tracing과 칼로리 소모량 기록용 개인 data log 앱이었으나, 발전하여 지금은 식습관 등이 포함되어 살빼는 목적을 실현시켜주는 앱이 되었고 전세계 user가 1500만명이 넘습니다. )
이런 식의 접근이 Genetics에도 시도가 되어 나가면 엄청난 혁신이 있을거라는 것을 GMIG 참여자 분들이라면 충분히 이해하시리라 생각 합니다.
하지만, Genomics의 연구 관점에서 보자면 이미 최첨단의 IT 기술들이 충분히 적용되고 있고, 경우에 따라서는 BT inspired IT 기술이 IT의 최첨단 기술이 되고 있습니다.
당장 현재 IT 최대 화도 cloud 컴퓨팅만 해도 유전체 데이터 분석이 major application domain으로 활발하게 연구 개발이 되고 있죠( KT에서 GenomeCloud를 베타 테스트 중입니다)
재범 대표님의 발표에서 구글의 Pagerank 알고리즘이 적용된 Gene priotization 연구를 언급하셨는데, 이런 연구는 gene expression 연구 초창기인 2000년대 초반 부터 minor 저널에 심심하면 한번씩 출판되던 내용입니다. 그냥 구글 서치해보면 2005년 논문이 상위에 뜨네요. 왜 이런 논문이 minor 저널에 출판되냐 하면, 당연히 value가 낮기 때문입니다.
즉, 이런 알고리즘을 적용하는 것은 fancy한 접근일 수는 있지만, '문제 해결'은 되지 않기 때문입니다. 기존의 방법론 보다 더 나은 해결책을 제시해 주지도 못하는데 그 이유는 간략하게 생물체의 variation은 엄청나기 때문이라는 것 정도만 여기에 언급해 둡니다. Gene expression과 관련해선 FDA의 MAQC( Microarray Quality Control ) 컨소시움의 연구를 통해 이런 점들이 이미 충분히 지적이 되었습니다.
(MAQC 내용을 정리한 제 블로그 글http://goldbio.blogspot.kr/2011/03/20.html )
MAQC는 당시 가능한 모든 통계적 분석법과 machine learning 알고리즘을 gene expression 분석에 적용해 보고, 가장 consistent하고 재현성 높은 분석 기준을 찾는 것을 목적으로 미국의 51개 major 유전체 연구기관이 참여한 대규모 study 였습니다.
기대는 뭔가 첨단의 hign-end 방법론이 best 일거라 기대했지만, 그 예상은 처참히 무너집니다. 최고는 초창기 부터 일반적으로 써왔던 fold change ( 그냥 단순히 case-control의 비율) 과 가장 간단한 t-test를 적절히 혼용하는 것이었죠.
재범 대표 님이 발표한 내용 중 network analysis 와 관련된 내용도 있었는데, network analysis 는 네트웍 분석이 바라바시에 의해 중요하게 부각된 초창기 부터 BT가 major application domain 으로 2000년대 초반부터 BT 특히나 bioinformatics에서는 일상적으로 다루어져 오고 있습니다. 바라바시가 쓴 그 유명한 저서 'Linked'에도 현재 테라젠의 박종화 연구소장님의 단백질 구조 도메인의 네트웍 연구가 소개되어 있을 정도 입니다.
심지어 network visualization 소프트웨어 중 최고로 인정되는 것이 바로 요즘 생물학 연구실에서 한명 쯤은 쓰고 있는 cytoscape라는 오픈 소스 소프트웨어 입니다. ( 이는 리로이 후드가 이끄는 ISB 에서 개발한 소프트웨어 )
사실 BT의 연구 측면에서만 보자면 IT 적 시각을 가진 사람들( bioinformatician )이 해야하는 역할은 새로운 시각으로 문제 해결의 새로운 가능성을 여는 일이라 봅니다. ( 이에 대해서도 일전에 정리해 둔 글을 참고로 링크 합니다http://goldbio.blogspot.kr/2011/02/blog-post.html )
Broad나 Sanger 연구소가 유전체 연구의 최고로 인정받는 이면에는 바로 이런 역할을 하는 사람들이 directing board로 참여하면서 연구의 혁신을 이끌기 때문입니다. ( sanger의 리차드 더빈, 팀 허바드 broad의 토드 골럽 등) 국외 뿐만 아니라, 국내에서도 유전체 연구를 선도하는 테라젠이나 서정선 교수님이 이끄는 서울대유전체연소(GMI) 등도 훌륭한 bioinformatician( 혹은 cross-functional researcher ) 들의 존재 때문에 선구적인 연구들을 진행할 수 있다고 봅니다.
글이 길어졌는데, 정리해 보면, IT의 UX/UI 기술들이 접목이 되어야 결국 진정한 personal genomics로 갈 수 있고, 대중화될 수 있다는 점. 하지만 연구자의 입장에서는 이미 충분히 첨단의 IT 기술이 적용되고 있고, 필요한 내용들은 대부분 쉽게 사용할 수 있는 application들이 존재하니, 활용을 하고, IT 기술에 대한 환상을 가질 필요는 없다는 점, 그리고 fancy한 기술 보다는 어떤 문제를 해결하는데 새로운, 참신한 idea를 간단한 IT 기법들로, crude한 상태라도 적용해보는 것이 중요할 수 있다는 아이디어들을 나누고 싶었습니다
Sunday, April 7, 2013
Friday, February 1, 2013
소비자 유전학( DTC: Direct To Consumer ) pioneer 회사들의 현재
소비자 유전학, DTC(Direct To Consumer ) genetics, 회사라고 불릴 수 있는 곳의 효시는 Google의 co-founder 세르게이 브린의 와이프 앤 워치키가 설립한 23andMe 라고 할 수 있다. 좀 더 엄밀히 따지면, deCODE genetics가 몇일 앞서지만, DTC 서비스라는 비즈니스 모델을 세상에 널리 알리며 소비자유전학이란 말을 만들어 내게 된 공은 역시 23andMe 로 돌리는 게 맞다.
이 두 회사의 설립 후, 암 전문의로 LA 헐리웃에서 활동하면서 이미 유명세를 떨치던 USC 의대 교수 데이빗 아구스가 디트리히 스테판과 함께 설립한 Navigenics가 23andme와 deCODE genetics의 뒤를 이어 세번째로 DTC 회사 리스트에 이름을 올렸다. ( 데이빗 아구스는 이 후, 스티브 잡스의 췌장암을 Genome 분석으로 치료하려는 시도를 하게 되면서, 잡스의 주치의 팀에도 합류하게 된다 )
전자공학도 이자 4개의 벤처기업을 런칭한 경험이 있던 제임스 플랜트는 이후 4번째 DTC 회사인 Pathway Genomics 를 설립한다.
23andme : 설립 2006년 4월, 2007년 11월 DTC 서비스 런칭
deCODE genetics : 설립 1996년 2007년 11월 DTC 서비스 런칭
Navigenics : 설립 2007년 11월, 2008년 4월 DTC 런칭
Pathway genomics : 설립 및 DTC 런칭 2008년
23andme 는 아무래도 Google의 후광 효과와 가장 싼 DTC 서비스를 내세워, 현재까지 가장 많은 고객을 유치했고( 2012년말 18만명), 최근에는 또다시5천억 5백억 이상의 투자를 받으며 서비스 가격을 $99까지 낮추어 100만 고객 유치를 기치로 내걸고 박차를 가하고 있다.
사라진 두 pioneer
deCODE genetics의 DTC 서비스였던 deCODEme 는 크게 각광 받지 못하였고, 최근 다국적 제약사 Amgen에 4천억 상당에 인수 되었다. Amgen의 deCODE 인수는 deCODE가 쌓아둔 Genome knowledge DB 및 분석 자원(인력과 방법론)을 활용한 신약 개발 과정의 혁신을 위해서라는 분석이 지배적이다. Navigenics 역시 크게 각광 받지 못하다가 최근 CLIA-lab 확보를 위해 노력하던 Life Technologies 에 500억 상당에 인수 되었다.
두 회사를 인수한 Amgen과 Life tech 모두 DTC 서비스의 중단을 선언했다. 엄밀하게 Navigenics 서비스는 이미 중단되었고, deCODE의 서비스인 deCODEme 는 중단할 예정이라고 발표가 난 상태다.
Pathway genomics는 최근 Blue shield of california 라는 캘리포니아 사보험 사와 계약하여 새로운 판로를 뚫었는데, 이 전 부터 다이어트, 올림픽 운동 선수 건강 가이드라인 등에 이용 등 마케팅을 꾸준히 하고, 해외 시장을 적극적으로 개척하는 등의 노력을 하며 비즈니스 안정화에 많은 노력을 기울이고 있는 것으로 보인다.
이 두 회사의 설립 후, 암 전문의로 LA 헐리웃에서 활동하면서 이미 유명세를 떨치던 USC 의대 교수 데이빗 아구스가 디트리히 스테판과 함께 설립한 Navigenics가 23andme와 deCODE genetics의 뒤를 이어 세번째로 DTC 회사 리스트에 이름을 올렸다. ( 데이빗 아구스는 이 후, 스티브 잡스의 췌장암을 Genome 분석으로 치료하려는 시도를 하게 되면서, 잡스의 주치의 팀에도 합류하게 된다 )
전자공학도 이자 4개의 벤처기업을 런칭한 경험이 있던 제임스 플랜트는 이후 4번째 DTC 회사인 Pathway Genomics 를 설립한다.
23andme : 설립 2006년 4월, 2007년 11월 DTC 서비스 런칭
deCODE genetics : 설립 1996년 2007년 11월 DTC 서비스 런칭
Navigenics : 설립 2007년 11월, 2008년 4월 DTC 런칭
Pathway genomics : 설립 및 DTC 런칭 2008년
23andme 는 아무래도 Google의 후광 효과와 가장 싼 DTC 서비스를 내세워, 현재까지 가장 많은 고객을 유치했고( 2012년말 18만명), 최근에는 또다시
사라진 두 pioneer
deCODE genetics의 DTC 서비스였던 deCODEme 는 크게 각광 받지 못하였고, 최근 다국적 제약사 Amgen에 4천억 상당에 인수 되었다. Amgen의 deCODE 인수는 deCODE가 쌓아둔 Genome knowledge DB 및 분석 자원(인력과 방법론)을 활용한 신약 개발 과정의 혁신을 위해서라는 분석이 지배적이다. Navigenics 역시 크게 각광 받지 못하다가 최근 CLIA-lab 확보를 위해 노력하던 Life Technologies 에 500억 상당에 인수 되었다.
두 회사를 인수한 Amgen과 Life tech 모두 DTC 서비스의 중단을 선언했다. 엄밀하게 Navigenics 서비스는 이미 중단되었고, deCODE의 서비스인 deCODEme 는 중단할 예정이라고 발표가 난 상태다.
Pathway genomics는 최근 Blue shield of california 라는 캘리포니아 사보험 사와 계약하여 새로운 판로를 뚫었는데, 이 전 부터 다이어트, 올림픽 운동 선수 건강 가이드라인 등에 이용 등 마케팅을 꾸준히 하고, 해외 시장을 적극적으로 개척하는 등의 노력을 하며 비즈니스 안정화에 많은 노력을 기울이고 있는 것으로 보인다.
Saturday, January 19, 2013
개인 게놈의 의학적 이용에서 제기되는 문제점과 미래
어제 아산병원 이종극 박사님의 Lead로 closed meeting으로 개최되었던 'Genomic Medicine Interest Group Meeting' 은 다양한 전공의 과목 의사분들에 의해 실제로 환자 치료나 연구에서 Genome 을 이용한 사례들이 넘쳐나는 흥미롭고 유익한 모임이었다.
모임의 말미에 아산병원 신수용 선생님이 개인 게놈 정보를 실제 병원에서 의학적으로 이용함에 있어 해결해야할 굉장히 중요한 문제점들을 제시해 주셨고, 이에 대해 다양한 시각의 의견들이 제시가 되었다. 흥미로운 주제이기도 하고, 또 앞으로 Genome의 산업적 이용에 있어 매우 중요한 사안들이기에, 이렇게 글로 정리하여 많은 사람들과 나누는 것이 의미 있을 거라는 판단에 정리해 본다.
( 기억력의 한계로 제대로 정리되지 않은 부분이 포함되었을 수 있고 상당 부분 논의된 내용이 빠져 있고, 개인적으로 인상 깊었던 두가지 사안에 대해서만 정리를 했습니다. 혹, 잘못된 부분/추가/수정 해야할 부분이 있으면 지적해 주시면 감사하겠습니다 )
1. 개인 게놈 raw data 의 저장 문제
문제 개괄
현재 NGS machine에서 한 사람의 whole human genome을 30x 로 읽으면 fastq raw data size는 180GB(3GB*30*2 -for fastq quality score space- )가 넘어가는 Big Data가 생성되고, 이를 기반으로 많은 환자들의 치료에 이용하는 병원과 같은 곳의 Genome center는 심각한 data storage 문제가 발생한다. 흔히 이에 대한 해결책으로 얘기되고 있는 Cloud 시스템은 a) 이용 요금이 생각보다 싸지 않고, b) 한 사람의 raw data 전송에 수일이 소요되는 전송 속도의 문제 등으로 인하여 적절한 해결책이 되지 못할 공산이 크다.
이종극 박사님 의견
병원에서 raw data를 계속 저장하고 있을 필요가 없다. 데이터 분석에 이용되는 환경( reference genome 과 분석에 이용되는 DB 들의 update )의 변화로 설령 추후에 분석 내용이 변경될 수 있다고 하더라도, 병원에서 genome data의 효용은 환자를 치료하는 시점( at the point of care )에 국한되고, 이 시점이 지난 시점은 이미 데이터 효용이 사라진 후기 때문에 raw data를 가지고 있을 필요가 없다.
최형진 선생님( 충북대 내분비내과 ) 의견
현장의 의사는 현실적으로 개개의 환자를 진료하는데 많은 시간을 쏟을 수 없다. 의사에게 전달되는 Genome 분석 결과는 한두페이지 짜리 최종 분석 보고서면 충분하다. 또한 현재 환자 치료에 이 분석 내용을 활용하였다면, 추후 다시 이 환자의 genome raw data를 재분석해 활용해 얻는 이익은 미미할 것이고, 현실적으로도 이런 재분석이 필요한 경우는 흔하지 않을 것이다.
결론적으로 raw data 저장에 여러가지 현실적 제약이 있다면, 병원이 raw data를 계속 가지고 있을 필요는 없다고 본다.
개인적 의견
Genome raw data storage는 기술의 발전이 자연스럽게 해결해 줄 것이라고 생각한다. 사실 현재의 raw data 사이즈가 큰 이유는 NGS 기계들의 떨어지는 성능 탓이다. DNA 30억개 문자로 3G면 되는 개인 게놈을 왜 30X 즉 30배로 읽을까? a) NGS 기계들이 200 base 단위 정도의 짧은 조각으로 게놈을 읽고, b) 그 마저도 1% 정도의 에러가 섞이기 때문이다. 그래서 전체 게놈의 30배 정도로 200bp 길이의 짧은 조각 DNA read 들을 생산해 '퍼즐 맞추기' 과정을 통해 문제 a 를 해결하고, 같은 부분에 읽힌 30개의 DNA를 확인해 b 문제를 해결하는 형태로 현재의 NGS 기계들이 작동하고 있기 때문이다.
현재 내부적으로 fine-tuning 과정을 거치고 있는 Oxford nanopore 의 4세대 DNA sequencer 가 그들의 주장대로 기계의 성능을 갖춰 출시된다면, 개인 게놈 raw data 사이즈는 혁신적으로 작아지게 된다. Oxford 의 read 길이는 평균 1만 base ( 2012년 초 기준) , error rate 4%( 역시 2012년 초 기준) 다. Oxford는 2012년말 보도 자료에서 error rate 이 1% 이내가 되기 전에는 시장에 출시하지 않겠다고 발표했다. 즉, 시장에 나오는 Oxford 제품은 평균 read 길이 최소 1만에 1% 이하의 error rate의 read를 생산하는 획기적인 DNA sequencer 가 된다.
Oxford 이후에도 Sequencer 성능은 꾸준히 개선될 것이고, 일정 시점에선 whole genome을 그냥 한번 읽어내면 되는 Sequencer 완성형 제품이 나오게 될 것이라고 생각한다. 그렇게 되면 그냥 개인 게놈은 3G 가 된다. 3G 라면 raw data 저장 문제도 그냥 해결이 된다. 현재 우리가 공짜로 쓰는 구글의 Gmail이 10G가 넘는다.
우정훈( Columbia medical school, Biomedical informatics PhD course & Geference Cofounder )의 의견
또하나의 가능성은 Genome sequencing 자체 가격이 떨어져, 마치 병원에서 필요할 때 마다 X-ray 를 찍듯, one time test 로 변모할 가능성이다. Whole genome sequencing 가격이 $1000 아래로 떨어진다면, Genome sequencing 이 필요할 때 마다 새로이 분석을 해도 하등의 문제가 없다 ( 지금 당장 MRI를 생각해 보면 명확하다). 이렇게 되면 굳이 raw data를 어딘가에 저장해 둘 필요가 없으면서, 미래의 분석 능력 향상 때 raw data를 새로이 분석해서 이용해야할 필요성이 완전히 사라지게 된다. 사실 이 시나리오가 가장 현실에 가까울 것 같다.
2. Genome 해석의 불완전성 으로 인한 책임 문제
문제 개괄
현재 Genome의 분석 과정에는 엄청나게 많은 error / variation 이 존재한다. 각 단계 마다 수많은 processing 방법들 중 하나를 선택할 수 있고, 이용할 수 있는 무수히 많은 소프트웨어들이 존재한다. 이들 방법론/소프트웨어들은 상당 부분 상이한 결과를 도출하는 경우가 많다. 잘못된 분석 단계 / 소프트웨어 이용으로 잘못된 결과를 도출하고 이에 기반하여 환자에게 잘못된 치료를 하게되는 문제 상황이 발생할 수 있다.
이종극 박사님, 최형진 선생님 의견
환자를 진료하는 의사 입장에서 여러가지 lab test 들과 진료 장비들을 일상적으로 사용하지만, 이들의 error율도 상당하다. 환자 치료에는 그 시점에서 state-of-art 검사 장비와 test 들을 이용하지만, 현재의 이런 최신 기법들을 훗날 돌아보면 모두 허점들이 있을 수밖에 없다. 하지만, 현재 시점에서 '최선'의 방법들을 선택할 수밖에 없는 것이고, 여기에 설령 error가 들어 있다손 치더라도, 이는 감수할 수 밖에 없는 부분이다.
Genome 의 이용도 이와 같은 맥락에서 바라볼 수 있다고 본다. 현 시점에서 개인의 Genome 분석에 error가 들어 있더라도, 이것이 현재 할 수 있는 최선이었다면, 그것으로 된 것이고, 추후 Genome 분석 방법이 upgrade 되어 error가 발견된다고 하더라도 이는 감수해야 하는 부분이다.
개인적 첨언
두분의 의견에 전적으로 동의하고, 현재 미국에서 이와 관련된 문제들에 어떻게 대처하고 있는지 현재 상황들의 정리해 본다.
Genome 치료의 임상 적용 사례중 가장 잘 알려진 사례는 스티브 잡스 건. 잡스의 개인 유전체 분석에는 지구상 최고의 의료팀이라 해도 과언이 아닌 드림팀이 구성되어 참여 했었고, 당연히 그 당시 잡스 유전체 분석에 State-of-art best practice가 적용되었다. 잡스는 게놈 분석을 위해서만 1억원의 비용을 지불했다. 의료진은 최선의 분석을 하고 치료에 이용했지만, 뚜렷한 치료법을 찾지 못했고 잡스는 사망했다. 잡스의 유전체 분석이 2010년경 행해졌기 때문에, 2년이 지난 지금 시점에서 다시 잡스의 게놈을 분석하면 분명 그 때에는 발견하지 못했던 어쩌면 잡스를 살릴 수도 있었던 중요한 내용을 발견할 가능성도 있다.
하지만, 지금 시점에서 잡스 게놈의 분석을 문제 삼는 사람은 아무도 없다. 잡스의 게놈은 치료가 필요한 바로 그 '시점'에서 필요한 정보였고, 그 당시 이를 최대한 활용했다면, 그것으로 된 것이고, 여기에 법적/도덕적 책임을 지을 하등의 이유가 없다.
잡스나 와트맨 같은 사례들이 나오고, Cancer 환자들에 Genome 분석을 이용하는 Foundation medicine 같은 회사가 구글/빌게이츠 등의 5천억 투자를 받아가며 성공적으로 비즈니스를 런칭했고, Drug 처방에 국한되는 Foundation medicine 보다 한발 더 나아가, 의사의 진료 현장에서 clinical decision 에 적극적으로 개입하는 '예측 모델'을 기반으로한 SV Bio 같은 회사들이 설립되고, 실제 뚜렷한 진단 부터가 어려운 희귀병 환자들을 우선적인 타겟으로 하여 비즈니스를 시작하고 있다.
현재의 시장을 관찰해 보면 개인 Genome의 의료계 도입은 현재 현대 의학으로 뚜렷한 답이 없는 부분에서 부터 적극적으로 도입되고 있는 것을 알 수 있다. 스티브 잡스와 같은 말기 암 화자, 루카스 와트맨 처럼 모든 가능한 치료법을 시도해 봤지만 실패하고 희망이 없는 암 환자, 병명도 모르는 희귀병 환자들.
Genome으로 인한 진단과 처방, 치료는 지금 상황에서 '이것이 정답' 이라고 얘기할 수 있는 임상 적용 사례는 몇몇 Drug에 대한 약물 반응성( Pharmacogenomics ) 분석 등 소수에 불과하다. 하지만, Genome 분석의 도입이 진단과 치료에 의미 있는 한 차원의 데이터를 더해 주고, 이를 기반으로 조금 더 정확하고, 조금 더 정밀한 진단과 치료가 가능해 지고, 또한 개선되어 나갈 것이라고 생각한다.
모임의 말미에 아산병원 신수용 선생님이 개인 게놈 정보를 실제 병원에서 의학적으로 이용함에 있어 해결해야할 굉장히 중요한 문제점들을 제시해 주셨고, 이에 대해 다양한 시각의 의견들이 제시가 되었다. 흥미로운 주제이기도 하고, 또 앞으로 Genome의 산업적 이용에 있어 매우 중요한 사안들이기에, 이렇게 글로 정리하여 많은 사람들과 나누는 것이 의미 있을 거라는 판단에 정리해 본다.
( 기억력의 한계로 제대로 정리되지 않은 부분이 포함되었을 수 있고 상당 부분 논의된 내용이 빠져 있고, 개인적으로 인상 깊었던 두가지 사안에 대해서만 정리를 했습니다. 혹, 잘못된 부분/추가/수정 해야할 부분이 있으면 지적해 주시면 감사하겠습니다 )
1. 개인 게놈 raw data 의 저장 문제
문제 개괄
현재 NGS machine에서 한 사람의 whole human genome을 30x 로 읽으면 fastq raw data size는 180GB(3GB*30*2 -for fastq quality score space- )가 넘어가는 Big Data가 생성되고, 이를 기반으로 많은 환자들의 치료에 이용하는 병원과 같은 곳의 Genome center는 심각한 data storage 문제가 발생한다. 흔히 이에 대한 해결책으로 얘기되고 있는 Cloud 시스템은 a) 이용 요금이 생각보다 싸지 않고, b) 한 사람의 raw data 전송에 수일이 소요되는 전송 속도의 문제 등으로 인하여 적절한 해결책이 되지 못할 공산이 크다.
이종극 박사님 의견
병원에서 raw data를 계속 저장하고 있을 필요가 없다. 데이터 분석에 이용되는 환경( reference genome 과 분석에 이용되는 DB 들의 update )의 변화로 설령 추후에 분석 내용이 변경될 수 있다고 하더라도, 병원에서 genome data의 효용은 환자를 치료하는 시점( at the point of care )에 국한되고, 이 시점이 지난 시점은 이미 데이터 효용이 사라진 후기 때문에 raw data를 가지고 있을 필요가 없다.
최형진 선생님( 충북대 내분비내과 ) 의견
현장의 의사는 현실적으로 개개의 환자를 진료하는데 많은 시간을 쏟을 수 없다. 의사에게 전달되는 Genome 분석 결과는 한두페이지 짜리 최종 분석 보고서면 충분하다. 또한 현재 환자 치료에 이 분석 내용을 활용하였다면, 추후 다시 이 환자의 genome raw data를 재분석해 활용해 얻는 이익은 미미할 것이고, 현실적으로도 이런 재분석이 필요한 경우는 흔하지 않을 것이다.
결론적으로 raw data 저장에 여러가지 현실적 제약이 있다면, 병원이 raw data를 계속 가지고 있을 필요는 없다고 본다.
개인적 의견
Genome raw data storage는 기술의 발전이 자연스럽게 해결해 줄 것이라고 생각한다. 사실 현재의 raw data 사이즈가 큰 이유는 NGS 기계들의 떨어지는 성능 탓이다. DNA 30억개 문자로 3G면 되는 개인 게놈을 왜 30X 즉 30배로 읽을까? a) NGS 기계들이 200 base 단위 정도의 짧은 조각으로 게놈을 읽고, b) 그 마저도 1% 정도의 에러가 섞이기 때문이다. 그래서 전체 게놈의 30배 정도로 200bp 길이의 짧은 조각 DNA read 들을 생산해 '퍼즐 맞추기' 과정을 통해 문제 a 를 해결하고, 같은 부분에 읽힌 30개의 DNA를 확인해 b 문제를 해결하는 형태로 현재의 NGS 기계들이 작동하고 있기 때문이다.
현재 내부적으로 fine-tuning 과정을 거치고 있는 Oxford nanopore 의 4세대 DNA sequencer 가 그들의 주장대로 기계의 성능을 갖춰 출시된다면, 개인 게놈 raw data 사이즈는 혁신적으로 작아지게 된다. Oxford 의 read 길이는 평균 1만 base ( 2012년 초 기준) , error rate 4%( 역시 2012년 초 기준) 다. Oxford는 2012년말 보도 자료에서 error rate 이 1% 이내가 되기 전에는 시장에 출시하지 않겠다고 발표했다. 즉, 시장에 나오는 Oxford 제품은 평균 read 길이 최소 1만에 1% 이하의 error rate의 read를 생산하는 획기적인 DNA sequencer 가 된다.
Oxford 이후에도 Sequencer 성능은 꾸준히 개선될 것이고, 일정 시점에선 whole genome을 그냥 한번 읽어내면 되는 Sequencer 완성형 제품이 나오게 될 것이라고 생각한다. 그렇게 되면 그냥 개인 게놈은 3G 가 된다. 3G 라면 raw data 저장 문제도 그냥 해결이 된다. 현재 우리가 공짜로 쓰는 구글의 Gmail이 10G가 넘는다.
우정훈( Columbia medical school, Biomedical informatics PhD course & Geference Cofounder )의 의견
또하나의 가능성은 Genome sequencing 자체 가격이 떨어져, 마치 병원에서 필요할 때 마다 X-ray 를 찍듯, one time test 로 변모할 가능성이다. Whole genome sequencing 가격이 $1000 아래로 떨어진다면, Genome sequencing 이 필요할 때 마다 새로이 분석을 해도 하등의 문제가 없다 ( 지금 당장 MRI를 생각해 보면 명확하다). 이렇게 되면 굳이 raw data를 어딘가에 저장해 둘 필요가 없으면서, 미래의 분석 능력 향상 때 raw data를 새로이 분석해서 이용해야할 필요성이 완전히 사라지게 된다. 사실 이 시나리오가 가장 현실에 가까울 것 같다.
2. Genome 해석의 불완전성 으로 인한 책임 문제
문제 개괄
현재 Genome의 분석 과정에는 엄청나게 많은 error / variation 이 존재한다. 각 단계 마다 수많은 processing 방법들 중 하나를 선택할 수 있고, 이용할 수 있는 무수히 많은 소프트웨어들이 존재한다. 이들 방법론/소프트웨어들은 상당 부분 상이한 결과를 도출하는 경우가 많다. 잘못된 분석 단계 / 소프트웨어 이용으로 잘못된 결과를 도출하고 이에 기반하여 환자에게 잘못된 치료를 하게되는 문제 상황이 발생할 수 있다.
이종극 박사님, 최형진 선생님 의견
환자를 진료하는 의사 입장에서 여러가지 lab test 들과 진료 장비들을 일상적으로 사용하지만, 이들의 error율도 상당하다. 환자 치료에는 그 시점에서 state-of-art 검사 장비와 test 들을 이용하지만, 현재의 이런 최신 기법들을 훗날 돌아보면 모두 허점들이 있을 수밖에 없다. 하지만, 현재 시점에서 '최선'의 방법들을 선택할 수밖에 없는 것이고, 여기에 설령 error가 들어 있다손 치더라도, 이는 감수할 수 밖에 없는 부분이다.
Genome 의 이용도 이와 같은 맥락에서 바라볼 수 있다고 본다. 현 시점에서 개인의 Genome 분석에 error가 들어 있더라도, 이것이 현재 할 수 있는 최선이었다면, 그것으로 된 것이고, 추후 Genome 분석 방법이 upgrade 되어 error가 발견된다고 하더라도 이는 감수해야 하는 부분이다.
개인적 첨언
두분의 의견에 전적으로 동의하고, 현재 미국에서 이와 관련된 문제들에 어떻게 대처하고 있는지 현재 상황들의 정리해 본다.
Genome 치료의 임상 적용 사례중 가장 잘 알려진 사례는 스티브 잡스 건. 잡스의 개인 유전체 분석에는 지구상 최고의 의료팀이라 해도 과언이 아닌 드림팀이 구성되어 참여 했었고, 당연히 그 당시 잡스 유전체 분석에 State-of-art best practice가 적용되었다. 잡스는 게놈 분석을 위해서만 1억원의 비용을 지불했다. 의료진은 최선의 분석을 하고 치료에 이용했지만, 뚜렷한 치료법을 찾지 못했고 잡스는 사망했다. 잡스의 유전체 분석이 2010년경 행해졌기 때문에, 2년이 지난 지금 시점에서 다시 잡스의 게놈을 분석하면 분명 그 때에는 발견하지 못했던 어쩌면 잡스를 살릴 수도 있었던 중요한 내용을 발견할 가능성도 있다.
하지만, 지금 시점에서 잡스 게놈의 분석을 문제 삼는 사람은 아무도 없다. 잡스의 게놈은 치료가 필요한 바로 그 '시점'에서 필요한 정보였고, 그 당시 이를 최대한 활용했다면, 그것으로 된 것이고, 여기에 법적/도덕적 책임을 지을 하등의 이유가 없다.
잡스나 와트맨 같은 사례들이 나오고, Cancer 환자들에 Genome 분석을 이용하는 Foundation medicine 같은 회사가 구글/빌게이츠 등의 5천억 투자를 받아가며 성공적으로 비즈니스를 런칭했고, Drug 처방에 국한되는 Foundation medicine 보다 한발 더 나아가, 의사의 진료 현장에서 clinical decision 에 적극적으로 개입하는 '예측 모델'을 기반으로한 SV Bio 같은 회사들이 설립되고, 실제 뚜렷한 진단 부터가 어려운 희귀병 환자들을 우선적인 타겟으로 하여 비즈니스를 시작하고 있다.
현재의 시장을 관찰해 보면 개인 Genome의 의료계 도입은 현재 현대 의학으로 뚜렷한 답이 없는 부분에서 부터 적극적으로 도입되고 있는 것을 알 수 있다. 스티브 잡스와 같은 말기 암 화자, 루카스 와트맨 처럼 모든 가능한 치료법을 시도해 봤지만 실패하고 희망이 없는 암 환자, 병명도 모르는 희귀병 환자들.
Genome으로 인한 진단과 처방, 치료는 지금 상황에서 '이것이 정답' 이라고 얘기할 수 있는 임상 적용 사례는 몇몇 Drug에 대한 약물 반응성( Pharmacogenomics ) 분석 등 소수에 불과하다. 하지만, Genome 분석의 도입이 진단과 치료에 의미 있는 한 차원의 데이터를 더해 주고, 이를 기반으로 조금 더 정확하고, 조금 더 정밀한 진단과 치료가 가능해 지고, 또한 개선되어 나갈 것이라고 생각한다.
Saturday, November 17, 2012
인간게놈프로젝트(Human Genome project)와 생물정보학(Bioinformatics)
Bioinformatics가 언론의 통해 기사화 되고 널리 알려지기 시작한 계기는 Genome Project 의 막바지인 1990년대 후반이 되면서 부터 였다. 인간게놈프로젝트( HGP: Human Genome Project)라 알려진 이 프로젝트는 10년의 시간에 걸쳐 미국 주도의 다국적 연구 컨소시움에 의해 총 30억달러 우리돈 3조원 이상이 소모된 달탐사 프로젝트 이래 최대의 과학 프로젝트 였다.
하지만, 1990년대 후반 크레이그 벤터( J. Craig Venter )가 셀레라(Celera genomics)사를 설립 대규모 자동 게놈 해독기를 장착하고 shortgun sequencing이라는 초고속 게놈 해독법을 이용해 인간 게놈을 분석하면서 이 지루한 프로젝트는 흥미진진한 소설 같은 상황으로 전개가 된다.
셀레라의 분석 기술로는 정부 주도의 다국적 팀에 의해 10년 이상이 소요될 것으로 예측되는 프로젝트를 불과 2-3년 안에 완료 할 수 있었고, 미생물 게놈을 빠른 시간 안에 분석 해 발표하면서 이는 기정 사실화 되었다. 정부 주도 하의 다국적 팀에게 이는 엄청난 위협이었고, 위기감을 불러 일으켰다. ( 과학자의 입장에서 보자면 수년간 노력한 일이 수포로 돌아가는 것과 마찬가지인데, 과학 연구에서 2등은 큰 의미가 없기 때문. 이와 관련한 스토리는 벤터의 자서전 Life decoded에 자세히 기록되어 있는데, 정부 주도 팀의 관료적 행태들은 구역질이 날 정도의 장면들이 많다. )
Shortgun genome sequencing
Shortgun sequencing 은 인간의 긴 30억개 염기 서열을 평균 500-1,000 개 염기 길이의 작은 단위로 잘라 읽은 후, 각각을 퍼즐 맞추기 식으로 이어 붙여 전체 30억개 염기 서열 부위를 완성하는 형태다.
Shotgun sequencing 방법은 얼핏 매우 간단해 보이지만, 이 방법은 Bioinformatics 가 없이는 애초에 불가능한 서열 분석 방법이었다.
Shortgun sequencing을 통해 예를 들어 세개의 염기 서열 조각이 아래와 같이 주어진다고 하면 어떻게 이어 붙여야 할까?
AGTGT, GTAAC, ACTAG
아래와 같이 이어 붙이면 된다.
AGTGT
GTAAC
ACTAG
--------------------------
AGTGTAACTAG
아래와 같은 방식도 가능하다.
ACTAG
AGTGT
GTAAC
--------------------------
ACTAGTGTAAC
어떤 쪽이 옳은 것일까? 이런 서열 조각이 수천만개 있다면 어떨까? 어떻게 이 조각들을 제대로 꿰어 맞출 수 있을까? 이는 굉장히 정교한 수학적 모델을 필요로 했으며, 엄청난 컴퓨팅 파워를 필요로 하는 문제로 정통 생물학자들이 해결할 수 있는 문제가 아니었다.
이 문제를 푸는데 적용할 만한 수학적 이론은 Shortest common superstring problem (SSP), Eulerian graph problem 등이 있었고, Genome sequencing에 적용할 만한 이론들로 Michael Waterman 등의 기여로 대체로 정립,개발되어 왔지만, 실제로 이를 대량의 염기 서열 조각을 이어 붙이는 시스템에 적용하여 제작된 전례가 없었다.
생물정보학자 전쟁 :: Eugene Myers vs. Jim Kent
Eugene Myers 를 필두로 하는 Bioinformatics 팀이 셀레라 측의 Shortgun sequencing을 위한 염기 서열 조각 맞추기 문제를 위한 시스템을 성공적으로 완성했다. Gene Myers라고 흔히 불리는 Eugene Myers 는 NCBI에서 1990년 지금까지 가장 광범위하고 성공적으로 사용되는 생물학 프로그램 BLAST 를 공동 개발한 Bioinformatics 초기 영웅 중 한명이었는데, 그가 Celera에 합류하여 라떼 커피를 친구삼아 밤낮 가리지 않고 일에 몰두한 덕에 비소로 셀레라의 Shortgun sequencing 기술이 완성될 수 있었다.
Shortgun sequencing 시스템을 하드웨어적, 소프트웨어적으로 완벽히 갖추고 인간 게놈 분석의 막바지에 다다르고 있었던 셀레라 사에 비해, 다국적팀( 인간게놈컨소시움)은 정부의 중재로 셀레라 사와 함께 인간 게놈 분석 초안을 발표하기로 약속한 몇달 전이 되기 까지 이 게놈 조각 퍼즐 맞추기( Sequence assembly ) 를 위한 시스템이 완성되지 않아 초조하게 발을 구르는 상황이었다.
10년의 노력, 3조원의 정부 연구비를 정당화 하기 위해서 이 시스템은 너무나 간절했던 것이었다. 이 때, UCSC 생물학과에서 박사과정 학생이던 Jim Kent (William James Kent )가 David Haussler 와의 협력 하에 학교에서 새로 구매한 50대의 컴퓨터를 리눅스 클러스터로 사용하여 한달 만에 이 시스템을 완성한다. Haussler와 협력이라고 하지만, 이 프로그램의 코드는 100% Kent 혼자서 한달 동안 밤낮없이 달려들어 완성한 것이었다. Kent가 완성한 이 프로그램을 이용해 비로소 다국적팀도 셀레라사에 뒤지지 않게 성공적으로 전체 인간 게놈 지도를 완성할 수 있었다. ( 정확히는 Kent의 프로그램을 이용한 다국적 팀이 3일 빨리 완성)
Kent가 생물학과 박사과정 학생이었지만, 사실 그는 3D graphics 엔진을 개발하는 컴퓨터 프로그래머로 일하던 전문 프로그래머였는데, 생물학에 매력을 느껴 community college에서 생물학 과목을 수강한 후, UCSC 생물학과 박사과정에 늦깍이 진학을 한 특이한 이력을 가지고 있던 학생이었다.
이 때의 성과를 바탕으로 UCSC는 UCSC genome browser라는 웹 기반 게놈 검색/분석 시스템을 서비스하게 되는데, 현재 이는 BLAST와 마찬가지로 생물학자들에게 매우 일상적으로 이용되는 Bioinformatics 서비스로 자리 메김했고, 덩달아 UCSC 는 그저그런 UC 계열 대학에서 세계 최정상의 게놈 연구 기관 중 한 곳으로 자리 메김 하게 되었다.
( Kent의 사례는 왜 다양한 background를 가진 직원/학생들을 창의적 업무를 요하는 회사/대학에서 뽑아야 하는지를 극명하게 보여주는 또하나의 좋은 예가 된다 )
Bioinformatics on the go
Bioinformatics 라는 분야는 Computational biology 라고 명명된 좀 더 수학적 이론에 치우친 분야를 토대로 게놈프로젝트 이전 1970년대 부터 이미 존재해 온 분야였지만, 인간게놈프로젝트를 기점으로 그 필요성과 역할이 크게 확대되었으며, 이에 대한 수요도 크게 늘어나게 되었다.
인간게놈프로젝트를 기점으로 비로소 독립된 Bioinformatics 교육 프로그램들이 미국의 대학들에 설립되기 시작했고( 연구 조직이 있었던 곳은 꾀나 있었지만, 독립적 학위 과정 프로그램을 가진 곳은 없었다), Michael Waterman이 1982년 부터 그 기틀을 잡아왔던 USC, 인간게놈프로젝트를 통해 유명해진 David Haussler 가 중심이 된 UCSC, 그외 Boston University 가 초기 독립된 Bioinformatics 학위 과정을 대학에 개설했는데, 이중 UCSC는 학부생 레벨( Bachelor degree)의 코스를 유일하게 설립해 운영을 시작했다.
국내에서는 2001년 숭실대학교에 최초의 학부 과정 학과가 개설(현재는 의생명공학부)되었고, 부산대학에 최초의 대학원 과정이 개설되었다. 2002년에는 서울대에 생물정보협동과정 대학원 과정이 개설되었고, 2003년에는 정문술 회장의 300억 기부로 KAIST에 Biosystems 이라는 이름으로 Bioinformatics 를 교육하는 학과(현재는 Bio & Brain Engineering 학과)가 만들어졌다.
인간게놈프로젝트에서 극명하게 드러난 것은 생물학이 이제 Large scale data 생산하는 시대에 접어들었고, 생물학이 이 large scale data의 분석을 통해 연구되는 Information science 즉 정보과학의 시대로 접어들었다는 사실이었다.
이는 게놈프로젝트 이후 생물학의 트렌드를 보면 극명히 드러나는데, 이 후에 생물학의 세부 분야들은 Genome 처럼 총체라는 뜻을 더해주는 -ome이 붙는 High-Thoughput data science 로 이름이 붙여졌고 ( Exressome, Proteome, Interactome, Metabolom , etc ) , 뛰어난 생물학 연구 팀에는 의례히 뛰어난 Bioinformatics 인력 혹은 공동연구팀이 함께 연구를 이끌어 가고 있음을 확인할 수 있다. 다시 말하면, 이제 첨단 생물학을 연구하기 위해서는 bioinformatics 로 대변되는 정보 과학적 분석 능력이 필수가 되었다는 말이 된다.
최근에 게놈 분석 비용이 획기적으로 낮아지면서, 게놈의 대중화와 이와 연계된 산업적 폭발이 목전에 와 있는데, 여기서도 게놈의 분석/관리/서비스를 위한 Bioinformatics 인력이 주도적 역할을 하게될 터인데,
게놈프로젝트 이후 많은 대학에 학위 과정이 개설되어 많은 인력을 배출해낸 미국에 비해 한국은 그나마 교육과정을 개설했던 학교들에서 오히려 Bioinformatics 이외의 분야들로 타겟을 바꾸어 학과를 포지셔닝 하면서, 제대로된 Bioinformatics 교육 커리큘럼을 갖춘 학교가 전무한 실정이다. 사실 미국을 제외하면 Bioinformatics 학위 과정이 활성화된 나라가 거의 없긴 한데, 그래서 자연히 앞으로의 Bioinformatics 분야도 미국이 주도적으로 발전시켜 나갈 수밖에 없지 않나 생각한다.
여담으로 현재 국내에서 중급 Bioinformatics 인력 조차도 구하기 쉽지 않은데, 앞으로 꾀나 오랜 시간 이런 흐름이 지속되지 않을가 조심스레 예측해 본다.
하지만, 1990년대 후반 크레이그 벤터( J. Craig Venter )가 셀레라(Celera genomics)사를 설립 대규모 자동 게놈 해독기를 장착하고 shortgun sequencing이라는 초고속 게놈 해독법을 이용해 인간 게놈을 분석하면서 이 지루한 프로젝트는 흥미진진한 소설 같은 상황으로 전개가 된다.
셀레라의 분석 기술로는 정부 주도의 다국적 팀에 의해 10년 이상이 소요될 것으로 예측되는 프로젝트를 불과 2-3년 안에 완료 할 수 있었고, 미생물 게놈을 빠른 시간 안에 분석 해 발표하면서 이는 기정 사실화 되었다. 정부 주도 하의 다국적 팀에게 이는 엄청난 위협이었고, 위기감을 불러 일으켰다. ( 과학자의 입장에서 보자면 수년간 노력한 일이 수포로 돌아가는 것과 마찬가지인데, 과학 연구에서 2등은 큰 의미가 없기 때문. 이와 관련한 스토리는 벤터의 자서전 Life decoded에 자세히 기록되어 있는데, 정부 주도 팀의 관료적 행태들은 구역질이 날 정도의 장면들이 많다. )
Shortgun genome sequencing
Shortgun sequencing 은 인간의 긴 30억개 염기 서열을 평균 500-1,000 개 염기 길이의 작은 단위로 잘라 읽은 후, 각각을 퍼즐 맞추기 식으로 이어 붙여 전체 30억개 염기 서열 부위를 완성하는 형태다.
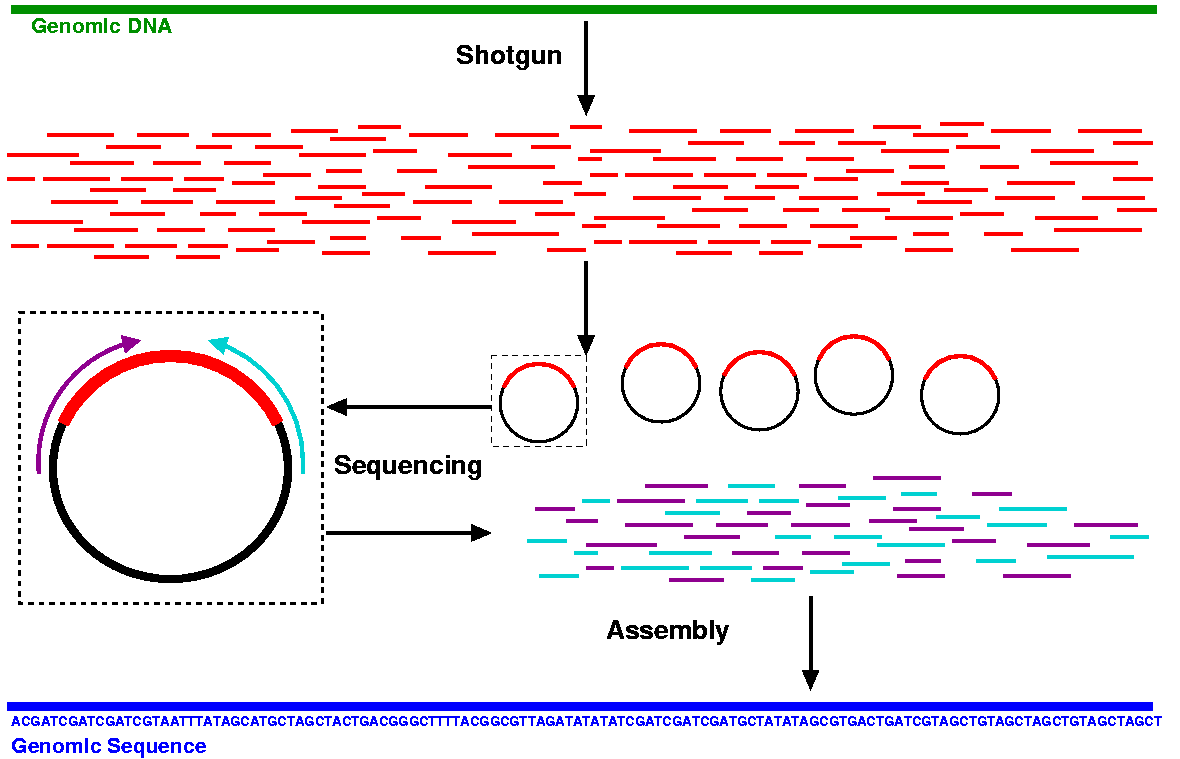 |
| Shortgun sequencing 방법 모식도 |
Shotgun sequencing 방법은 얼핏 매우 간단해 보이지만, 이 방법은 Bioinformatics 가 없이는 애초에 불가능한 서열 분석 방법이었다.
Shortgun sequencing을 통해 예를 들어 세개의 염기 서열 조각이 아래와 같이 주어진다고 하면 어떻게 이어 붙여야 할까?
AGTGT, GTAAC, ACTAG
아래와 같이 이어 붙이면 된다.
AGTGT
GTAAC
ACTAG
--------------------------
AGTGTAACTAG
아래와 같은 방식도 가능하다.
ACTAG
AGTGT
GTAAC
--------------------------
ACTAGTGTAAC
어떤 쪽이 옳은 것일까? 이런 서열 조각이 수천만개 있다면 어떨까? 어떻게 이 조각들을 제대로 꿰어 맞출 수 있을까? 이는 굉장히 정교한 수학적 모델을 필요로 했으며, 엄청난 컴퓨팅 파워를 필요로 하는 문제로 정통 생물학자들이 해결할 수 있는 문제가 아니었다.
이 문제를 푸는데 적용할 만한 수학적 이론은 Shortest common superstring problem (SSP), Eulerian graph problem 등이 있었고, Genome sequencing에 적용할 만한 이론들로 Michael Waterman 등의 기여로 대체로 정립,개발되어 왔지만, 실제로 이를 대량의 염기 서열 조각을 이어 붙이는 시스템에 적용하여 제작된 전례가 없었다.
생물정보학자 전쟁 :: Eugene Myers vs. Jim Kent
Eugene Myers 를 필두로 하는 Bioinformatics 팀이 셀레라 측의 Shortgun sequencing을 위한 염기 서열 조각 맞추기 문제를 위한 시스템을 성공적으로 완성했다. Gene Myers라고 흔히 불리는 Eugene Myers 는 NCBI에서 1990년 지금까지 가장 광범위하고 성공적으로 사용되는 생물학 프로그램 BLAST 를 공동 개발한 Bioinformatics 초기 영웅 중 한명이었는데, 그가 Celera에 합류하여 라떼 커피를 친구삼아 밤낮 가리지 않고 일에 몰두한 덕에 비소로 셀레라의 Shortgun sequencing 기술이 완성될 수 있었다.
Shortgun sequencing 시스템을 하드웨어적, 소프트웨어적으로 완벽히 갖추고 인간 게놈 분석의 막바지에 다다르고 있었던 셀레라 사에 비해, 다국적팀( 인간게놈컨소시움)은 정부의 중재로 셀레라 사와 함께 인간 게놈 분석 초안을 발표하기로 약속한 몇달 전이 되기 까지 이 게놈 조각 퍼즐 맞추기( Sequence assembly ) 를 위한 시스템이 완성되지 않아 초조하게 발을 구르는 상황이었다.
10년의 노력, 3조원의 정부 연구비를 정당화 하기 위해서 이 시스템은 너무나 간절했던 것이었다. 이 때, UCSC 생물학과에서 박사과정 학생이던 Jim Kent (William James Kent )가 David Haussler 와의 협력 하에 학교에서 새로 구매한 50대의 컴퓨터를 리눅스 클러스터로 사용하여 한달 만에 이 시스템을 완성한다. Haussler와 협력이라고 하지만, 이 프로그램의 코드는 100% Kent 혼자서 한달 동안 밤낮없이 달려들어 완성한 것이었다. Kent가 완성한 이 프로그램을 이용해 비로소 다국적팀도 셀레라사에 뒤지지 않게 성공적으로 전체 인간 게놈 지도를 완성할 수 있었다. ( 정확히는 Kent의 프로그램을 이용한 다국적 팀이 3일 빨리 완성)
Kent가 생물학과 박사과정 학생이었지만, 사실 그는 3D graphics 엔진을 개발하는 컴퓨터 프로그래머로 일하던 전문 프로그래머였는데, 생물학에 매력을 느껴 community college에서 생물학 과목을 수강한 후, UCSC 생물학과 박사과정에 늦깍이 진학을 한 특이한 이력을 가지고 있던 학생이었다.
이 때의 성과를 바탕으로 UCSC는 UCSC genome browser라는 웹 기반 게놈 검색/분석 시스템을 서비스하게 되는데, 현재 이는 BLAST와 마찬가지로 생물학자들에게 매우 일상적으로 이용되는 Bioinformatics 서비스로 자리 메김했고, 덩달아 UCSC 는 그저그런 UC 계열 대학에서 세계 최정상의 게놈 연구 기관 중 한 곳으로 자리 메김 하게 되었다.
( Kent의 사례는 왜 다양한 background를 가진 직원/학생들을 창의적 업무를 요하는 회사/대학에서 뽑아야 하는지를 극명하게 보여주는 또하나의 좋은 예가 된다 )
Bioinformatics on the go
Bioinformatics 라는 분야는 Computational biology 라고 명명된 좀 더 수학적 이론에 치우친 분야를 토대로 게놈프로젝트 이전 1970년대 부터 이미 존재해 온 분야였지만, 인간게놈프로젝트를 기점으로 그 필요성과 역할이 크게 확대되었으며, 이에 대한 수요도 크게 늘어나게 되었다.
인간게놈프로젝트를 기점으로 비로소 독립된 Bioinformatics 교육 프로그램들이 미국의 대학들에 설립되기 시작했고( 연구 조직이 있었던 곳은 꾀나 있었지만, 독립적 학위 과정 프로그램을 가진 곳은 없었다), Michael Waterman이 1982년 부터 그 기틀을 잡아왔던 USC, 인간게놈프로젝트를 통해 유명해진 David Haussler 가 중심이 된 UCSC, 그외 Boston University 가 초기 독립된 Bioinformatics 학위 과정을 대학에 개설했는데, 이중 UCSC는 학부생 레벨( Bachelor degree)의 코스를 유일하게 설립해 운영을 시작했다.
국내에서는 2001년 숭실대학교에 최초의 학부 과정 학과가 개설(현재는 의생명공학부)되었고, 부산대학에 최초의 대학원 과정이 개설되었다. 2002년에는 서울대에 생물정보협동과정 대학원 과정이 개설되었고, 2003년에는 정문술 회장의 300억 기부로 KAIST에 Biosystems 이라는 이름으로 Bioinformatics 를 교육하는 학과(현재는 Bio & Brain Engineering 학과)가 만들어졌다.
인간게놈프로젝트에서 극명하게 드러난 것은 생물학이 이제 Large scale data 생산하는 시대에 접어들었고, 생물학이 이 large scale data의 분석을 통해 연구되는 Information science 즉 정보과학의 시대로 접어들었다는 사실이었다.
이는 게놈프로젝트 이후 생물학의 트렌드를 보면 극명히 드러나는데, 이 후에 생물학의 세부 분야들은 Genome 처럼 총체라는 뜻을 더해주는 -ome이 붙는 High-Thoughput data science 로 이름이 붙여졌고 ( Exressome, Proteome, Interactome, Metabolom , etc ) , 뛰어난 생물학 연구 팀에는 의례히 뛰어난 Bioinformatics 인력 혹은 공동연구팀이 함께 연구를 이끌어 가고 있음을 확인할 수 있다. 다시 말하면, 이제 첨단 생물학을 연구하기 위해서는 bioinformatics 로 대변되는 정보 과학적 분석 능력이 필수가 되었다는 말이 된다.
최근에 게놈 분석 비용이 획기적으로 낮아지면서, 게놈의 대중화와 이와 연계된 산업적 폭발이 목전에 와 있는데, 여기서도 게놈의 분석/관리/서비스를 위한 Bioinformatics 인력이 주도적 역할을 하게될 터인데,
게놈프로젝트 이후 많은 대학에 학위 과정이 개설되어 많은 인력을 배출해낸 미국에 비해 한국은 그나마 교육과정을 개설했던 학교들에서 오히려 Bioinformatics 이외의 분야들로 타겟을 바꾸어 학과를 포지셔닝 하면서, 제대로된 Bioinformatics 교육 커리큘럼을 갖춘 학교가 전무한 실정이다. 사실 미국을 제외하면 Bioinformatics 학위 과정이 활성화된 나라가 거의 없긴 한데, 그래서 자연히 앞으로의 Bioinformatics 분야도 미국이 주도적으로 발전시켜 나갈 수밖에 없지 않나 생각한다.
여담으로 현재 국내에서 중급 Bioinformatics 인력 조차도 구하기 쉽지 않은데, 앞으로 꾀나 오랜 시간 이런 흐름이 지속되지 않을가 조심스레 예측해 본다.
Thursday, August 30, 2012
스티브 잡스 vs. 루카스 와트맨 :: 개인유전체 정보를 이용한 암 치료 혁명
스티브 잡스는 사망 후에도 히트작을 하나 만들어 내는데, 전세계에서 엄청나게 팔려나간 그의 자서전이 바로 그것이다. 잘 알려져 있다 시피 스티브 잡스는 치료법이 거의 없는 췌장암에 걸려 죽음을 앞두고 있다가, 치료가 가능한 희귀한 형태의 췌장암이라는 것이 밝혀지고 수술을 통해 6년을 더 살다가 다시 암이 재발해 숨을 거뒀다. 앞서 언급한 스티브 잡스의 자서전엔 그가 겪은 암의 치유 과정이 좀 더 자세히 묘사되어 있는데, 대체 의학에 대한 그의 믿음 때문에 치료 시기를 놓쳐 걷잡을 수 없는 상태로 암이 악화되어 갔고, 그의 의료진은 할 수 있는 모든 것을 다 시도할 수밖에 없는 상황에 놓여 있었다.
게놈 분석으로 암 치료를 시도한 스티브 잡스
앞서 언급했듯, 췌장암은 특별한 치료 방법도 없고, 약도 개발되어 있지 않다. 무기력하게 죽음을 기다릴 수밖에 없는 상황의 스티브 잡스의 치료에 지구상 최고 수준의 의료진(스탠포드, 하버드 등의 의료 연합팀) 이 실낱같은 희망을 가지고 시도한 마지막 암 치료 방법은 '개인 유전체 분석' 이었다.
잡스의 의료진이 선택한 게놈 분석은 전장 지놈 분석( Whole Genome Sequencing ) 으로 인간의 30억개 DNA 서열을 모두 읽어 분석하는 방식이다. 이런 whole genome 분석은 2001년 인간게놈프로젝트(HGP: Human Genome Project ) 에서 30조를 들여서야 가능했지만, 지금은 천만원 단위로 그 가격이 낮아져있고, 잡스의 게놈을 분석할 당시인 2009년~2010년 경엔 천만원 정도를 들이면 가능한 수준으로 낮아져 있었는데, 잡스의 사망 후 밝혀진 내용에 따르면 이에 십만달러 우리돈 1억 정도가 들었다고 한다. 현재 실험실 레벨에서의 전장 게놈 분석 비용은 3백만원 아래다.
암 환자의 게놈을 읽는 것이 어떻게 암의 치료로 이어질까? 컨셉은 매우 간단하다. 간략하게 서머리 해보면,
위와 같은 순서로 요약할 수 있다. 문제의 원인이 되는 DNA 를 찾고, 이 DNA 가 포함된 유전자를 표적으로 하는 약을 찾아 처방한다는 것이 게놈 분석을 통한 암 치료의 핵심이다. 여기서 중요한 포인트는 문제가 되는 유전자를 표적으로 하는 약은 '암치료 약'이 아닐 수 있다는 사실이다. 평범한 감기약도 암을 유발하는 DNA 가 포함된 유전자를 타겟으로 하면 암을 치료하는 약이 될 수 있다는 사실이다.
Why Genome Sequencing for Cancer Treatment?
이쯤에서 상기해야 하는 사실 ' 우리는 서로 모두 다른 게놈 DNA 서열을 가지고 있다'
치료 방법이 없는 스티브 잡스의 게놈을 왜 분석했을까? 그래봐야 치료법이 없는 암을 앓고 있지 않았나? 맞다. 하지만 그의 게놈은 지구상 그 누구의 게놈과도 다른 유일한 DNA 서열로 이루어져 있다. 그의 암을 일으킨 DNA 들은 기존의 암치료제들이 표적으로 삼지는 않지만, 이미 존재하는 다른 약들은 표적으로 삼을 가능성이 존재한다. 이 '개인 특이적 DNA 다형성' 이 암 치료에 게놈 분석을 도입하고, 효과적으로 이용될 수 있는 이유다.
애석하게 스티브 잡스의 게놈 분석에서는 치료에 효과적으로 사용할 만한 정보를 찾는데 실패했고, 그는 죽음을 받아들여야 했다.
잡스가 죽고난 이후, 2012년 게놈 분석을 이용하여 암을 효과적으로 치유한 사례가 뉴욕타임즈 기사에 실리면서 화제가 되고 있는데, 더욱 화제가 될 만한 것은 이를 적용한 대상의 암 환자가 워싱턴 대학에서 암을 연구하는 의사라는 사실이다.
루카스 와트맨( Lukas Wartman )
루카스 와트맨은 대학 시절 여름 방학 때 잠깐 병원에서 일하면서 암 연구에 매료되었고, 세인트루이스 소재 워싱턴 대학 의과대학에 진학하여 암 연구 의사가 되기로 결심한다. 하지만 2002년 그의 의과대학 마지막 해 스탠포드 대학 레지던트 프로그램 인터뷰가 있던 날 아침 처음 겪어보는 엄청난 피로감과 함께 이런 계획들은 난관에 봉착하게 된다.
백혈병( 정확히는 급성 림프구 백혈병 , ALL : Acute Lymphoblastic Leukemia ) 에 걸렸던 것이다. 그는 스탠포드에서 레지던트 프로그램을 하려던 계획은 취소하고, 워싱턴 대학에 남아 치료와 레지던트 프로그램을 병행한다. 2년여의 화학요법 치료를 마치고 건강히 5년이 지나 암이 치유된 것 처럼 보였지만, 암은 다시 재발한다. 남동생의 골수를 이식받고난지 3년지 지난 후에도 다시 암이 재발한다.
담당 의료팀은 모든 방법을 시도해 봤지만, 아무 것도 효과가 없었다.
더이상 가능한 방법이 없던 시점, 마지막 희망은 그의 게놈을 분석하여 치료를 하는 획기적 기술이었다. 워싱턴 대학 유전학 연구소의 책임자 리차드 윌슨과 엘라인 마디스 팀이 그의 게놈을 분석하기 시작했다.
DNA가 아닌 RNA 가 암을 치료하다
연구팀은 먼저 그의 DNA 를 분석했다. 예상대로 많은 변형 DNA 들이 발견되었지만, 이들 DNA 를 표적으로 하는 약이 없었기 때문에 아무런 도움이 되지 못했다. 그래서 그들은 또다른 유전체 정보인 RNA 로 방향을 틀었다. 그리고 예상치 못한 발견을 하게 된다.
연구팀은 백혈병 세포에서 FLT3 라는 유전자가 광범위하게 발현이 되고 있음을 알아냈다. FLT3 유전자는 정상 세포에서 세포를 성장시키는 역할에 관여한다. 암이 무엇인가? 세포의 끝없는 성장이다. 곧, 과발현된 FLT3 유전자는 와트맨의 암 세포를 빠르게 성장시키는 암의 원인 유전자가 되고 있다는 가정을 할 수 있게 된다.
이 보다 더 와트맨에게 희망을 준 사실은 Sutent 혹은 Sunitinib 이라 불리는 FLT3 유전자를 표적으로 하는 신장암 약이 막 허가를 받아 시판되고 있었다는 점이다. 하지만 약값은 하루 $330불로 매우 비쌌고, 와트맨의 보험 회사는 약값 지불을 거부했다.
보험 회사가 두번이나 그의 간청을 무시하자, 그는 Sutent 의 제조사 화이자(Pfizer) 에 접촉해 그의 연봉으론 7개월 보름 분의 약값 밖에 지불할 수 없다며 약 제공을 간청했지만 여전히 묵살 당하고 만다. 동료 의사들의 도움으로 약을 제공받게 된 와트맨은 약을 복용한지 2주 백혈병 세포로 가득했던 골수가 완전히 깨끗해져 있음을 생검 검사를 통해 확인하게 된다. 이후 여러가지 검사를 통해서도 그의 백혈병은 치유되었음이 확인된다. ( Cytometry, FISH 테스트 등)
이후 화이자는 와트맨에거 Sutent 를 무료로 제공하기로 결정했고, 그는 지금까지 건강하게 지내고 있다. 워싱턴 대학 병원은 와트맨과 같은 유전적 변이가 암에서 발견될 때, Sutent 를 처방하여 치료할 수 있도록 하기 위한 Clinical trial testing 의 런칭을 준비중이라고 한다.
스티브 잡스, 와트맨, 그리고 당신
같은 게놈 분석을 암치료에 적용하고도 스티브 잡스는 죽었고, 와트맨은 치유되었다. 와트맨은 운이 좋았다. 운 좋게 그의 변이 유전자를 표적으로 하는 약이 개발되어 있었고, 스티브 잡스는 아마도 이런 유전적 변이와 이를 표적으로 하는 약을 찾을 수 없었을 것이다.
하지만 와트맨과 같은 사례는 앞으로 더 많은 숫자와 주기로 반복될 것이다. 이런 사례들은 각각 새로운 암 치료 '유전자 변이-표적 약' 조합을 가지게 되고, 암으로 고통받는 수많은 사람들중 상당수를 구원하게 될 것이다.
스티브 잡스, 와트맨 처럼 게놈 분석을 하기 위해선 아직도 꾀나 많은 돈이 든다. 하지만 유전체 분석 비용은 가파르게 떨어지고 있고, 암 유전체 분석만을 위해서 구체적으로 상품을 꾸린다면 지금도 천만원 보다 적은 돈으로 이런 치료를 시도해 볼 수 있다 ( 마진을 거의 붙이지 않는다면 ).
우리는 이런 기술이 가능한 세상에 살고 있고, 이런 기술이 앞으로 암에 걸린 당신을 치유하게 될 것이다.
 |
| 재발한 암에 고통받던 시기 스티브 잡스의 마지막 애플 컨퍼런스 기조연설 |
게놈 분석으로 암 치료를 시도한 스티브 잡스
앞서 언급했듯, 췌장암은 특별한 치료 방법도 없고, 약도 개발되어 있지 않다. 무기력하게 죽음을 기다릴 수밖에 없는 상황의 스티브 잡스의 치료에 지구상 최고 수준의 의료진(스탠포드, 하버드 등의 의료 연합팀) 이 실낱같은 희망을 가지고 시도한 마지막 암 치료 방법은 '개인 유전체 분석' 이었다.
잡스의 의료진이 선택한 게놈 분석은 전장 지놈 분석( Whole Genome Sequencing ) 으로 인간의 30억개 DNA 서열을 모두 읽어 분석하는 방식이다. 이런 whole genome 분석은 2001년 인간게놈프로젝트(HGP: Human Genome Project ) 에서 30조를 들여서야 가능했지만, 지금은 천만원 단위로 그 가격이 낮아져있고, 잡스의 게놈을 분석할 당시인 2009년~2010년 경엔 천만원 정도를 들이면 가능한 수준으로 낮아져 있었는데, 잡스의 사망 후 밝혀진 내용에 따르면 이에 십만달러 우리돈 1억 정도가 들었다고 한다. 현재 실험실 레벨에서의 전장 게놈 분석 비용은 3백만원 아래다.
암 환자의 게놈을 읽는 것이 어떻게 암의 치료로 이어질까? 컨셉은 매우 간단하다. 간략하게 서머리 해보면,
- 암 환자의 정상 세포와 암세포의 게놈을 읽는다.
- 두 게놈을 비교하여 암세포에 변형이 일어난 DNA 를 찾는다.
- 변형이 일어난 DNA 로 인한 비정상적 세포 기작을 일으키는 유전자를 찾는다.
- 3번 과정에서 찾은 유전자를 타겟으로 하는 약의 처방 이나 시술을 시행한다.
위와 같은 순서로 요약할 수 있다. 문제의 원인이 되는 DNA 를 찾고, 이 DNA 가 포함된 유전자를 표적으로 하는 약을 찾아 처방한다는 것이 게놈 분석을 통한 암 치료의 핵심이다. 여기서 중요한 포인트는 문제가 되는 유전자를 표적으로 하는 약은 '암치료 약'이 아닐 수 있다는 사실이다. 평범한 감기약도 암을 유발하는 DNA 가 포함된 유전자를 타겟으로 하면 암을 치료하는 약이 될 수 있다는 사실이다.
Why Genome Sequencing for Cancer Treatment?
이쯤에서 상기해야 하는 사실 ' 우리는 서로 모두 다른 게놈 DNA 서열을 가지고 있다'
치료 방법이 없는 스티브 잡스의 게놈을 왜 분석했을까? 그래봐야 치료법이 없는 암을 앓고 있지 않았나? 맞다. 하지만 그의 게놈은 지구상 그 누구의 게놈과도 다른 유일한 DNA 서열로 이루어져 있다. 그의 암을 일으킨 DNA 들은 기존의 암치료제들이 표적으로 삼지는 않지만, 이미 존재하는 다른 약들은 표적으로 삼을 가능성이 존재한다. 이 '개인 특이적 DNA 다형성' 이 암 치료에 게놈 분석을 도입하고, 효과적으로 이용될 수 있는 이유다.
애석하게 스티브 잡스의 게놈 분석에서는 치료에 효과적으로 사용할 만한 정보를 찾는데 실패했고, 그는 죽음을 받아들여야 했다.
잡스가 죽고난 이후, 2012년 게놈 분석을 이용하여 암을 효과적으로 치유한 사례가 뉴욕타임즈 기사에 실리면서 화제가 되고 있는데, 더욱 화제가 될 만한 것은 이를 적용한 대상의 암 환자가 워싱턴 대학에서 암을 연구하는 의사라는 사실이다.
루카스 와트맨( Lukas Wartman )
루카스 와트맨은 대학 시절 여름 방학 때 잠깐 병원에서 일하면서 암 연구에 매료되었고, 세인트루이스 소재 워싱턴 대학 의과대학에 진학하여 암 연구 의사가 되기로 결심한다. 하지만 2002년 그의 의과대학 마지막 해 스탠포드 대학 레지던트 프로그램 인터뷰가 있던 날 아침 처음 겪어보는 엄청난 피로감과 함께 이런 계획들은 난관에 봉착하게 된다.
백혈병( 정확히는 급성 림프구 백혈병 , ALL : Acute Lymphoblastic Leukemia ) 에 걸렸던 것이다. 그는 스탠포드에서 레지던트 프로그램을 하려던 계획은 취소하고, 워싱턴 대학에 남아 치료와 레지던트 프로그램을 병행한다. 2년여의 화학요법 치료를 마치고 건강히 5년이 지나 암이 치유된 것 처럼 보였지만, 암은 다시 재발한다. 남동생의 골수를 이식받고난지 3년지 지난 후에도 다시 암이 재발한다.
담당 의료팀은 모든 방법을 시도해 봤지만, 아무 것도 효과가 없었다.
 |
| 와트맨( 왼쪽 ) 과 그의 보스이자 연구 동료, 그리고 주치의인 존 디페르시오( John Dipercio ) |
더이상 가능한 방법이 없던 시점, 마지막 희망은 그의 게놈을 분석하여 치료를 하는 획기적 기술이었다. 워싱턴 대학 유전학 연구소의 책임자 리차드 윌슨과 엘라인 마디스 팀이 그의 게놈을 분석하기 시작했다.
DNA가 아닌 RNA 가 암을 치료하다
연구팀은 먼저 그의 DNA 를 분석했다. 예상대로 많은 변형 DNA 들이 발견되었지만, 이들 DNA 를 표적으로 하는 약이 없었기 때문에 아무런 도움이 되지 못했다. 그래서 그들은 또다른 유전체 정보인 RNA 로 방향을 틀었다. 그리고 예상치 못한 발견을 하게 된다.
연구팀은 백혈병 세포에서 FLT3 라는 유전자가 광범위하게 발현이 되고 있음을 알아냈다. FLT3 유전자는 정상 세포에서 세포를 성장시키는 역할에 관여한다. 암이 무엇인가? 세포의 끝없는 성장이다. 곧, 과발현된 FLT3 유전자는 와트맨의 암 세포를 빠르게 성장시키는 암의 원인 유전자가 되고 있다는 가정을 할 수 있게 된다.
이 보다 더 와트맨에게 희망을 준 사실은 Sutent 혹은 Sunitinib 이라 불리는 FLT3 유전자를 표적으로 하는 신장암 약이 막 허가를 받아 시판되고 있었다는 점이다. 하지만 약값은 하루 $330불로 매우 비쌌고, 와트맨의 보험 회사는 약값 지불을 거부했다.
보험 회사가 두번이나 그의 간청을 무시하자, 그는 Sutent 의 제조사 화이자(Pfizer) 에 접촉해 그의 연봉으론 7개월 보름 분의 약값 밖에 지불할 수 없다며 약 제공을 간청했지만 여전히 묵살 당하고 만다. 동료 의사들의 도움으로 약을 제공받게 된 와트맨은 약을 복용한지 2주 백혈병 세포로 가득했던 골수가 완전히 깨끗해져 있음을 생검 검사를 통해 확인하게 된다. 이후 여러가지 검사를 통해서도 그의 백혈병은 치유되었음이 확인된다. ( Cytometry, FISH 테스트 등)
이후 화이자는 와트맨에거 Sutent 를 무료로 제공하기로 결정했고, 그는 지금까지 건강하게 지내고 있다. 워싱턴 대학 병원은 와트맨과 같은 유전적 변이가 암에서 발견될 때, Sutent 를 처방하여 치료할 수 있도록 하기 위한 Clinical trial testing 의 런칭을 준비중이라고 한다.
스티브 잡스, 와트맨, 그리고 당신
같은 게놈 분석을 암치료에 적용하고도 스티브 잡스는 죽었고, 와트맨은 치유되었다. 와트맨은 운이 좋았다. 운 좋게 그의 변이 유전자를 표적으로 하는 약이 개발되어 있었고, 스티브 잡스는 아마도 이런 유전적 변이와 이를 표적으로 하는 약을 찾을 수 없었을 것이다.
하지만 와트맨과 같은 사례는 앞으로 더 많은 숫자와 주기로 반복될 것이다. 이런 사례들은 각각 새로운 암 치료 '유전자 변이-표적 약' 조합을 가지게 되고, 암으로 고통받는 수많은 사람들중 상당수를 구원하게 될 것이다.
스티브 잡스, 와트맨 처럼 게놈 분석을 하기 위해선 아직도 꾀나 많은 돈이 든다. 하지만 유전체 분석 비용은 가파르게 떨어지고 있고, 암 유전체 분석만을 위해서 구체적으로 상품을 꾸린다면 지금도 천만원 보다 적은 돈으로 이런 치료를 시도해 볼 수 있다 ( 마진을 거의 붙이지 않는다면 ).
우리는 이런 기술이 가능한 세상에 살고 있고, 이런 기술이 앞으로 암에 걸린 당신을 치유하게 될 것이다.
Saturday, July 28, 2012
평범한 사람들이 모인 팀 VS. 특급 전문가 1명 :: 간단한 확률로 본 집단 지성의 힘
우리는 전문가의 힘을 과대 평가하는 경향이 있다. 실제로 인류 역사를 한단계 진보시킬 만한 희대의 천재들이 존재했던 것이 사실이다. 뉴턴이 그랬고, 아인슈타인이 그랬다. 가까이는 스티브 잡스도 있다. 하지만, 우리가 일상적으로 접하는 상황에서의 전문가는 이런 레벨의 사람들이 아닐 확률이 높다.
대게 우리가 접하는 전문가 혹은 '천재'라고 칭송하는 주변의 사람들은 특정 분야에 오랫동안 열심히 일해오며 '전문성'을 키워온 사람들이다. 이런 사람들은 '척하면 아' 하고 알 정도로 그 분야에서 벌어지는 일들을 놀라울 정도로 빠르고 효과적으로 처리한다. 가까이는 내 옆의 김대리가 될 수도 있고, 좀 더 넓게는 어느회사의 김 과장, 어느 대학 교수 아무개와 같은 식으로 특정 분야의 전문가들은 돋보이는 존재다. 그래서 언론에서도 어떤 사안에 대한 깊이 있는 통찰과 전망이 필요할 때 이런 전문가들을 찾아 나선다.
과연 전문가 1명의 파워는 얼마나 막강한 것일까? 최근에 번역 출간된 책 '앨빈 토플러와 작별하라' ( 원제: Future bubble ) 에서는 전문가들의 예측은 그냥 한귀로 듣고 한귀로 흘리는게 좋을정도로 형편 없다는 사실을 방대한 사례들을 바탕으로 설명한다.
그럼, 좀 더 범위를 좁혀서, 내가 일하는 회사, 혹은 학교 연구팀에서 이런 최고의 실력을 갖춘 전문가의 의견은 어느 정도로 유의할까?
특급 전문가 vs. 평범한 사람들로 이루어진 팀
특정 전문가가 p1의 확률로 올바른 결정을 내린다고 하자. 동시에 전문가 보다는 못한 p2 의 확률로 올바른 결정을 내리는 사람들이 모인 팀이 있고, 다수결로 팀의 결정을 내린다고 하자. 어느 쪽이 더 높은 빈도로 올바른 결정을 내릴까?
특정 전문가가 올바른 결정을 내릴 확률 P(s)=p1
p2의 확률로 올바른 결정을 내리는 팀원 N명의 다수결이 올바른 결정일 확률 P(s) 는 아래와 같다.
=1-\sum_{k=0 }^{\left \lfloor n/2 \right \rfloor }_n{C}_{k} *p^{k} (1-p)^{n-k} "p(Correct answer| Team)=)1-\sum_{k=0 }^{\left \lfloor n/2 \right \rfloor }_n{C}_{k} *p^{k} (1-p)^{n-k}")
이를 계산해서 그래프로 그려보면 아래와 같다.
특급 전문가를 이기는 평범하지만 특별한 집단
위의 그래프에서 보여지듯, p1의 확률이 0.5 이상인 경우( 즉, 동전던지기 보다는 나은 확률인 경우 ), 특급 전문가 1인 보다는 평범한 팀이 더 높은 확률로 올바른 결정을 내릴 수 있다. 75%확률로 옳은 결정을 내리는 7명이 모이면 93%의 확률로 옳은 결정을 내릴 수 있고, 11명이 모이면 96.5% 확률로 옳은 결정을 내릴 수 있다. 이는 90% 확률로 옳은 결정을 내리는 특급 전문가보다 평범한 팀이 더 옳은 판단을 내릴 수 있다는 말이다. 하지만 이런 결론을 내리기 위해서 몇가지 가정이 필요하다.
1. 독립적인 사고를 하는 팀원
보통 집단 내에서는 집단의 의견을 좌지우지하는 강력한 권한을 가진 '팀장' 혹은 이에 상응하는 역할을 하는 팀원이 존재하는 경우가 많다. 동등한 권한을 가진 팀원이라 하더라도 똑똑하다고 인정받거나, 평소 성과가 좋아 많은 사람들의 신뢰를 받는 '특급 팀원'이 바로 이런 이들. 팀장 내지 이런 '특급 팀원'의 의견을 '보통의 팀원'들이 쉽게 따라가는 경우가 많다. 정말 같은 의견을 가진 경우도 있겠지만, 그렇지 않은 경우가 많을 것이라 본다.
팀장이나 특급 팀원, 좀 더 넓게는 지도교수, 회사의 사장 등 어떤 사람 앞에서도 독립적으로 사고할 수 있는 사람만이 '올바른 결정을 내리는 자그마한 팀'이 가져야 할 팀원이다. 다양한 경력의 팀원들이라면 같은 분야의 팀원으로 구성된 팀보다 상대적으로 좀 더 독립적인 사고능력이 높은 팀이라고 할 수 있을 것이다.
2. 동등한 결정 권한
독립적인 사고를 하는 팀원으로 구성된 팀이라도 자신의 의견으로 팀의 의사를 결정지어 버리는 권위적인 팀장이 버티고 있다면 특급 전문가를 앞서는 소수의 팀으로서의 능력은 사라지고 만다. 팀원들의 판단이 동등한 권한(1/N) 을 가지고, 이들의 의견이 다수의 의견으로 취합될 때, 비로소 특급전문가를 이기는 강한 팀이 될 수 있다.
팀원 숫자는 홀수가 낫다, 짝수라면 ...
확률 계산을 따르자면, 홀수 인원의 팀은 짝수 인원의 팀보다 더 높은 확률로 옳은 결정을 내린다. 홀수인 팀은 3명을 예로 들자면, 옳은 의견을 낼 1명과 그렇지 않은 1명을 상쇄하고 남는 나머지 한명이 옳은 확률을 내면 팀은 옳은 의견을 선택한다. 하지만 4명으로 이루어진 짝수 인원의 팀이 옳은 의견을 내기 위해선 3명이 옳은 의견을 내야 한다.
'정'과 '반' 이 홀수팀에선 평균적으로 상쇄되고 남은 한명이 옳은 의견을 내면 팀이 옳은 의견을 내는데 반해, 짝수팀은 '정'과 '반'이 같은 경우에 팀은 틀린 결론을 내게 되는데서 이런 차이가 나타난다.
짝수팀에서 나타나는 이런 문제를 해결 하기 위해선 , '정'과 '반'의 숫자가 같은 경우, 랜덤으로 한명( 혹은 가장 확률이 높은 투표권자)을 선정하고 그의 의견에 따르는 장치를 마련하면 홀수팀+1의 짝수팀이 더 높은 확률로 옳은 의견을 낼 수 있다.
큰 회사가 더 믿을 만 하다, 더 잘한다?
큰 회사, 똑똑한 사람들이 많이 모인 그룹이 소수의 팀, 작은 회사보다 더 강력할 것이라고 생각하는 경우가 많다. 하지만, 이 모델에 따르자면 10명이 넘어가면서 그 차이는 거의 존재 하지 않는다.
오히려 실질적으로는 큰 그룹의 의사소통 비용 ( 들이는 돈, 시간, 장소 등등) 이 기하 급수적으로 늘어나기 때문에, 소수의 강력한 팀에 비해 서로 의견 조율도 어렵고, 결정 과정도 기민하지 못하다. 가장 큰 문제는 숫자가 많기 때문에 이런 경우에 팀장 몇명, 혹은 대표 1인의 의견이 매우 강력하게 의사결정에 적용이 된다는 점이다. 위의 분석에서도 보여지듯, 강력한 1인 보다는 적당히 강력한 다수의 의견이 옳을 확률이 더 높다.
2-3명으로 시작하는 실리콘밸리의 많은 기업들이 신화가 된데는 이런 의사소통 과정의 효율성과 동등한 권한을 가진 동료들의 확률 높은 의사 결정 과정이 뒷받침 되었던 것도 분명히 큰 역할을 했으리라 생각한다.
새로운 의사결정을 많이 하며 빠르게 나아가야 유리한 '새로운 산업', 즉 첨단 산업의 경우에 소수의 팀으로 이루어진 작은 회사들이 대기업에 앞설 수밖에 없는 이유를 바로 이런 의사소통과 결정 과정에서 찾을 수 있지 않나 생각한다.
마무리
'옳은 판단'을 하는 특정한 시스템을 가정하고 고작 두개의 변수만을 가지고 통계 계산을 해 시뮬레이션 한 결과이기 때문에, 이 글에서 도출된 내용들을 그대로 실생활에 적용하는데는 무리가 따르지만, 미지의 문제에 대해 옳은 판단을 내리고자 하는 다양한 상황에서, 독립적인 사고를 하며, 동등한 권한을 가진 그룹이라면 글에서 시사하는 내용들을 한번쯤 떠올려 적용해 보는 것도 의미 있으리라 ...
더 읽을 거리
대게 우리가 접하는 전문가 혹은 '천재'라고 칭송하는 주변의 사람들은 특정 분야에 오랫동안 열심히 일해오며 '전문성'을 키워온 사람들이다. 이런 사람들은 '척하면 아' 하고 알 정도로 그 분야에서 벌어지는 일들을 놀라울 정도로 빠르고 효과적으로 처리한다. 가까이는 내 옆의 김대리가 될 수도 있고, 좀 더 넓게는 어느회사의 김 과장, 어느 대학 교수 아무개와 같은 식으로 특정 분야의 전문가들은 돋보이는 존재다. 그래서 언론에서도 어떤 사안에 대한 깊이 있는 통찰과 전망이 필요할 때 이런 전문가들을 찾아 나선다.
과연 전문가 1명의 파워는 얼마나 막강한 것일까? 최근에 번역 출간된 책 '앨빈 토플러와 작별하라' ( 원제: Future bubble ) 에서는 전문가들의 예측은 그냥 한귀로 듣고 한귀로 흘리는게 좋을정도로 형편 없다는 사실을 방대한 사례들을 바탕으로 설명한다.
그럼, 좀 더 범위를 좁혀서, 내가 일하는 회사, 혹은 학교 연구팀에서 이런 최고의 실력을 갖춘 전문가의 의견은 어느 정도로 유의할까?
특급 전문가 vs. 평범한 사람들로 이루어진 팀
특정 전문가가 p1의 확률로 올바른 결정을 내린다고 하자. 동시에 전문가 보다는 못한 p2 의 확률로 올바른 결정을 내리는 사람들이 모인 팀이 있고, 다수결로 팀의 결정을 내린다고 하자. 어느 쪽이 더 높은 빈도로 올바른 결정을 내릴까?
특정 전문가가 올바른 결정을 내릴 확률 P(s)=p1
p2의 확률로 올바른 결정을 내리는 팀원 N명의 다수결이 올바른 결정일 확률 P(s) 는 아래와 같다.
이를 계산해서 그래프로 그려보면 아래와 같다.
 |
| p1 = 개개인이 옳은 판단을 내릴 확률, P( correct | number of team ) = x명으로 구성된 팀이 옳은 판단을 내릴 확률. 각각의 선은 구성원 멤버 숫자가 다른 팀들을 의미한다. 검은색 선의 경우 팀이 1명으로 구성된 팀 , 즉 특급 전문가 1인의 판단을 의미한다. 그래프 위쪽의 회색 선은 P(correct | number of team) = 0.95 즉, 95%로 옳은 판단을 내릴 확률을 표시하는 선이다. |
특급 전문가를 이기는 평범하지만 특별한 집단
위의 그래프에서 보여지듯, p1의 확률이 0.5 이상인 경우( 즉, 동전던지기 보다는 나은 확률인 경우 ), 특급 전문가 1인 보다는 평범한 팀이 더 높은 확률로 올바른 결정을 내릴 수 있다. 75%확률로 옳은 결정을 내리는 7명이 모이면 93%의 확률로 옳은 결정을 내릴 수 있고, 11명이 모이면 96.5% 확률로 옳은 결정을 내릴 수 있다. 이는 90% 확률로 옳은 결정을 내리는 특급 전문가보다 평범한 팀이 더 옳은 판단을 내릴 수 있다는 말이다. 하지만 이런 결론을 내리기 위해서 몇가지 가정이 필요하다.
1. 독립적인 사고를 하는 팀원
보통 집단 내에서는 집단의 의견을 좌지우지하는 강력한 권한을 가진 '팀장' 혹은 이에 상응하는 역할을 하는 팀원이 존재하는 경우가 많다. 동등한 권한을 가진 팀원이라 하더라도 똑똑하다고 인정받거나, 평소 성과가 좋아 많은 사람들의 신뢰를 받는 '특급 팀원'이 바로 이런 이들. 팀장 내지 이런 '특급 팀원'의 의견을 '보통의 팀원'들이 쉽게 따라가는 경우가 많다. 정말 같은 의견을 가진 경우도 있겠지만, 그렇지 않은 경우가 많을 것이라 본다.
팀장이나 특급 팀원, 좀 더 넓게는 지도교수, 회사의 사장 등 어떤 사람 앞에서도 독립적으로 사고할 수 있는 사람만이 '올바른 결정을 내리는 자그마한 팀'이 가져야 할 팀원이다. 다양한 경력의 팀원들이라면 같은 분야의 팀원으로 구성된 팀보다 상대적으로 좀 더 독립적인 사고능력이 높은 팀이라고 할 수 있을 것이다.
2. 동등한 결정 권한
독립적인 사고를 하는 팀원으로 구성된 팀이라도 자신의 의견으로 팀의 의사를 결정지어 버리는 권위적인 팀장이 버티고 있다면 특급 전문가를 앞서는 소수의 팀으로서의 능력은 사라지고 만다. 팀원들의 판단이 동등한 권한(1/N) 을 가지고, 이들의 의견이 다수의 의견으로 취합될 때, 비로소 특급전문가를 이기는 강한 팀이 될 수 있다.
팀원 숫자는 홀수가 낫다, 짝수라면 ...
확률 계산을 따르자면, 홀수 인원의 팀은 짝수 인원의 팀보다 더 높은 확률로 옳은 결정을 내린다. 홀수인 팀은 3명을 예로 들자면, 옳은 의견을 낼 1명과 그렇지 않은 1명을 상쇄하고 남는 나머지 한명이 옳은 확률을 내면 팀은 옳은 의견을 선택한다. 하지만 4명으로 이루어진 짝수 인원의 팀이 옳은 의견을 내기 위해선 3명이 옳은 의견을 내야 한다.
 |
| 붉은 색이 팀원 수가 홀수인 경우, 검은색이 팀원 수가 짝수인 경우. 같은 모양의 점이 들어간 붉은색과 검은색 라인에서 검은색이 팀원 수가 1명 더 많은 짝수 팀이고, 팀원이 늘어났지만, 오히려 y축의 옳은 선택을 할 확률 P 가 낮아짐을 확인할 수 있다. ( 라인이 조밀해 실제 눈으로 판별은 몇몇 점에 대해서만 가능한 듯 하지만 ) |
'정'과 '반' 이 홀수팀에선 평균적으로 상쇄되고 남은 한명이 옳은 의견을 내면 팀이 옳은 의견을 내는데 반해, 짝수팀은 '정'과 '반'이 같은 경우에 팀은 틀린 결론을 내게 되는데서 이런 차이가 나타난다.
짝수팀에서 나타나는 이런 문제를 해결 하기 위해선 , '정'과 '반'의 숫자가 같은 경우, 랜덤으로 한명( 혹은 가장 확률이 높은 투표권자)을 선정하고 그의 의견에 따르는 장치를 마련하면 홀수팀+1의 짝수팀이 더 높은 확률로 옳은 의견을 낼 수 있다.
큰 회사가 더 믿을 만 하다, 더 잘한다?
큰 회사, 똑똑한 사람들이 많이 모인 그룹이 소수의 팀, 작은 회사보다 더 강력할 것이라고 생각하는 경우가 많다. 하지만, 이 모델에 따르자면 10명이 넘어가면서 그 차이는 거의 존재 하지 않는다.
오히려 실질적으로는 큰 그룹의 의사소통 비용 ( 들이는 돈, 시간, 장소 등등) 이 기하 급수적으로 늘어나기 때문에, 소수의 강력한 팀에 비해 서로 의견 조율도 어렵고, 결정 과정도 기민하지 못하다. 가장 큰 문제는 숫자가 많기 때문에 이런 경우에 팀장 몇명, 혹은 대표 1인의 의견이 매우 강력하게 의사결정에 적용이 된다는 점이다. 위의 분석에서도 보여지듯, 강력한 1인 보다는 적당히 강력한 다수의 의견이 옳을 확률이 더 높다.
2-3명으로 시작하는 실리콘밸리의 많은 기업들이 신화가 된데는 이런 의사소통 과정의 효율성과 동등한 권한을 가진 동료들의 확률 높은 의사 결정 과정이 뒷받침 되었던 것도 분명히 큰 역할을 했으리라 생각한다.
새로운 의사결정을 많이 하며 빠르게 나아가야 유리한 '새로운 산업', 즉 첨단 산업의 경우에 소수의 팀으로 이루어진 작은 회사들이 대기업에 앞설 수밖에 없는 이유를 바로 이런 의사소통과 결정 과정에서 찾을 수 있지 않나 생각한다.
마무리
'옳은 판단'을 하는 특정한 시스템을 가정하고 고작 두개의 변수만을 가지고 통계 계산을 해 시뮬레이션 한 결과이기 때문에, 이 글에서 도출된 내용들을 그대로 실생활에 적용하는데는 무리가 따르지만, 미지의 문제에 대해 옳은 판단을 내리고자 하는 다양한 상황에서, 독립적인 사고를 하며, 동등한 권한을 가진 그룹이라면 글에서 시사하는 내용들을 한번쯤 떠올려 적용해 보는 것도 의미 있으리라 ...
더 읽을 거리
- 관련된 내용의 블로그 글, 대중의 지혜( http://geference.blogspot.com/2011/11/wisdom-of-crowds.html )도 한번 읽어보기를 추천한다.
- 이 글에 언급된 상황의 확률 문제는 The flippant juror 라는 고전 확률 문제를 변형한 것이다.
Wednesday, May 9, 2012
jQuery Mobile on PhoneGap :: Cross-domain page request 설정
jQuery mobile 로 remote 서버의 페이지에 접근하는 경우는 두가지다.
1. ajax 처리
ajax처리는 javascript 혹은 jQuery로 간단히 처리할 수 있다.
아래의 jQuery 코드는 www.geference.com 의 exam.php를 실행하고 그 결과를 data로 받아 경고창에 뿌려준다. jQuery mobile 에서도 잘 작동한다.
2. remote 서버 페이지로 페이지 이동
jQuery mobile 의 페이지 이동은 $.mobile.changePage() 함수가 담당한다.
하지만 아래의 코드는 제대로 작동하지 않는다.
기본적으로 jQuery mobile은 cross-domain 페이지 이동이 안 되도록 설정 되어 있다.
cross-domain 페이지 이동을 가능케 하려면, 아래 설정을 app의 시동시에 등록해 두어야 한다.
phonegap 1.3.0 버전을 기준으로 테스트해 본 결과, $.support.cors 는 기본 설정이 true로 되어 있어, 따로 설정을 하지 않아도 되지만, $.mobile.allowCrossDomainPages 는 기본이 false로 되어 있어 명시적으로 true로 설정해 주어야 한다.
phonegap에서 white list 설정을 풀어주어야 하는 것도 잊으면 안 된다.
1. ajax 처리
ajax처리는 javascript 혹은 jQuery로 간단히 처리할 수 있다.
아래의 jQuery 코드는 www.geference.com 의 exam.php를 실행하고 그 결과를 data로 받아 경고창에 뿌려준다. jQuery mobile 에서도 잘 작동한다.
$.post( 'www.geference.com/exam.php' , function(data){ alert( data) } )
2. remote 서버 페이지로 페이지 이동
jQuery mobile 의 페이지 이동은 $.mobile.changePage() 함수가 담당한다.
하지만 아래의 코드는 제대로 작동하지 않는다.
$.mobile.changePage( 'www.geference.com/exam.php')
기본적으로 jQuery mobile은 cross-domain 페이지 이동이 안 되도록 설정 되어 있다.
cross-domain 페이지 이동을 가능케 하려면, 아래 설정을 app의 시동시에 등록해 두어야 한다.
$.support.cors= true;$.mobile.allowCrossDomainPages = true;
phonegap 1.3.0 버전을 기준으로 테스트해 본 결과, $.support.cors 는 기본 설정이 true로 되어 있어, 따로 설정을 하지 않아도 되지만, $.mobile.allowCrossDomainPages 는 기본이 false로 되어 있어 명시적으로 true로 설정해 주어야 한다.
phonegap에서 white list 설정을 풀어주어야 하는 것도 잊으면 안 된다.
Subscribe to:
Posts (Atom)