URL : http://genomebiology.com/content/pdf/gb-2007-8-11-r252.pdf
Gene mutation이 phenotype에는 과연 어떤 영향을 미칠까?
이는 SNP 연구의 핵심이 되는 질문이다.
Species간, 각 human 개체간의 genetic variation이
어떤 영향을 끼쳐, species간 혹은 개체 간의 variation을
만들어 낼까?
이 논문에서는 protein complex를 이용해 gene mutation
의 phenotypic effect를 설명한다.
Thursday, November 29, 2007
Blast options for ortholog gene finding
URL :http://bioinformatics.oxfordjournals.org/cgi/content/abstract/btm585v1
서로 다른 두 species 간의 ortholog 를 찾는 방법은
Reciplocal best blast hit,
Reciplocal best distance hit
방법 등 여러가지가 있는데, blast를 이용한 방법이
사용의 편의성에 기인해 널리 쓰인다.
위의 논문에서는 Blast option을 바꾸는 것 만으로
ortholog finding accuracy를 높이는 방법을
제안한다.
서로 다른 두 species 간의 ortholog 를 찾는 방법은
Reciplocal best blast hit,
Reciplocal best distance hit
방법 등 여러가지가 있는데, blast를 이용한 방법이
사용의 편의성에 기인해 널리 쓰인다.
위의 논문에서는 Blast option을 바꾸는 것 만으로
ortholog finding accuracy를 높이는 방법을
제안한다.
Tuesday, November 27, 2007
왜 장기 투자를 해야 하는가?
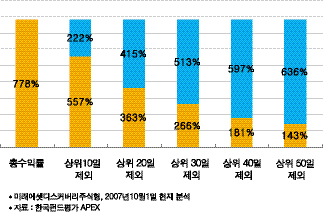
국내 주식 시작에 투자하는 대한민국 대표펀드
미래에셋 디스커버리주식 1호는 현재까지 약 778%의
수익률을 마크하고 있다.
펀드가 시작된 2001년에 1억을 넣어놓고, 그대로 유지하기만
했어도 현재 약 8억 8천만원으로 불릴 수 있었다는 얘기다.
같은 돈으로 같은 기간 동안 수익률이 많이 오를 때 마다 넣었다
뺐다를 반복한 사람의 수익률은 어떨까? 얼핏 생각해서 많이 올랐을 때
팔고, 많이 떨어졌을 때 다시 매수를 한다면 그냥 넣어두고 있었던
것 보다 더 좋은 수익률을 기록할 수 있지 않을까 생각하기 쉽지만,
이는 주가가 언제 오르고, 떨어질지를 정확하게 예측할 때만 가능한
한 마디로 신이 아니고는 할 수 없는 일이다.
이런 식으로 투자를 하면서 주가가 많이 올랐던 상위 10일만을
투자 하지 못했다고 한다면 어떨까? 차트에서 보는 바와 같이
220% 가량의 수익률이 날아간다. 상위 20일, 30일 로 가면
수익률이 절반에도 못 미친다는 것을 알 수 있다.
7년여의 기간 중 단 수십일 펀드 투자를 계속 유지하느냐,
하지 않았느냐에 따라 엄청난 수익률의 차이가 발생하는 것이다.
투자의 기본은 장기 투자, 분산 투자다.
문제는 이 기본을 지킬 수 있는가다.
매일매일의 신문 기사와 증시 시황에 흔들리고
불안에 떨 만큼 '투자'가 불안하다면
안전한 은행에 넣어놓고 콩고물 같은
이자만 받으며 만족해야 할 수밖에 없다.
Wednesday, November 21, 2007
Fun&Co
Article source : Bioinformatics, 23, 2725, 2007
두 그룹의 microarray data set의 functional difference를
비교하고자 할 때 ( e.g. 서로 다른 tissue, disease vs. normal 등)
사용할 수 있는 방법으로 fun&co 이라는 web server가 공개되었다.
Procedure는 아래와 같다.
1. 각 그룹의 intensity를 rank로 변환
2. 가능한 모든pair probe set에 대해 spearman correlation coefficient 계산
3. pair probe set이 동일한 gene을 detection하는 경우가 아닐 때, 연관된 GOmain term을 counting
4. 각 그룹의 counting 된 GO term set을 비교하여, 그룹과 Over-correlated or under-correlated 된 GO 를 선정
다른 방법들과 구분되는 특이한 점이라면,
하나의 GO term을 지칭하는 Pair gene이
correlation되는 경우 연관된 GO term에만
의미를 두었다는 것이다.
이는 multi data set comparision의 경우 몇가지 advantage를 가지는데
1. 각 data set에서 DEG test를 할 필요가 없다는 점
2. 따라서 normal condition에 대한 고려가 필요없는 경우 ( 서로 다른 tissue 비교와 같은 경우), 각 data set에서 관련된 array만 고려하면 된다는 점
등이 된다.
두 그룹의 microarray data set의 functional difference를
비교하고자 할 때 ( e.g. 서로 다른 tissue, disease vs. normal 등)
사용할 수 있는 방법으로 fun&co 이라는 web server가 공개되었다.
Procedure는 아래와 같다.
1. 각 그룹의 intensity를 rank로 변환
2. 가능한 모든pair probe set에 대해 spearman correlation coefficient 계산
3. pair probe set이 동일한 gene을 detection하는 경우가 아닐 때, 연관된 GOmain term을 counting
4. 각 그룹의 counting 된 GO term set을 비교하여, 그룹과 Over-correlated or under-correlated 된 GO 를 선정
다른 방법들과 구분되는 특이한 점이라면,
하나의 GO term을 지칭하는 Pair gene이
correlation되는 경우 연관된 GO term에만
의미를 두었다는 것이다.
이는 multi data set comparision의 경우 몇가지 advantage를 가지는데
1. 각 data set에서 DEG test를 할 필요가 없다는 점
2. 따라서 normal condition에 대한 고려가 필요없는 경우 ( 서로 다른 tissue 비교와 같은 경우), 각 data set에서 관련된 array만 고려하면 된다는 점
등이 된다.
Tuesday, November 20, 2007
Human PAML Brower
Human gene들에 대한 evolutionary rate을 PAML 패키지를
이용해 계산한 결과를 담은 DB가 공개 되었다.
Human PAML Browser : http://mendel.gene.cwru.edu/adamslab/pbrowser.py
Human gene은 약 22,000~28,000 로 추정되는데,
여기서는 UCSC multispecies genome alignment에
의해 얻어진 ortholog 13,721개에 대한 결과를 담고있다.
PAML을 돌리기 위해 DNA sequence pair, Protein sequence pair
들을 각각 준비해야 하고, computation time도 꾀나 걸린다는
점을 생각해 볼 때, 필요할 때 마다 관심있는 gene의 PAML
결과를 검색할 때 유용할 것 같다.
NAR paper : http://nar.oxfordjournals.org/cgi/reprint/gkm764v1?ck=nck
이용해 계산한 결과를 담은 DB가 공개 되었다.
Human PAML Browser : http://mendel.gene.cwru.edu/adamslab/pbrowser.py
Human gene은 약 22,000~28,000 로 추정되는데,
여기서는 UCSC multispecies genome alignment에
의해 얻어진 ortholog 13,721개에 대한 결과를 담고있다.
PAML을 돌리기 위해 DNA sequence pair, Protein sequence pair
들을 각각 준비해야 하고, computation time도 꾀나 걸린다는
점을 생각해 볼 때, 필요할 때 마다 관심있는 gene의 PAML
결과를 검색할 때 유용할 것 같다.
NAR paper : http://nar.oxfordjournals.org/cgi/reprint/gkm764v1?ck=nck
Monday, November 19, 2007
CellMontage : Gene expression alignment tool
http://cellmontage.cbrc.jp/cgi-bin/index.cgi?page=1
Gene expression 정보가 Public database인 GEO와 ArrayExpress에
축적되는 양이 점점 많아지면서, DB에 들어있는 expression 정보에의
접근이 중요한 Research topic으로 떠오르고 있다.
Sequence alignment와 마찬가지로, 특정한 Gene expression profile과
비슷한 Profile들을 찾고, 묶어내고 하는 일련의 과정들이 바로 이 topic의
목적이 된다.
Bioinfo2007에 발표한 내 논문에서는 실험 단위의 Gene expression 정보들을
clustering하는 방법을 논의했는데, 여기서는 이 보다 작은 sample 단위의
expression profile을 clustering하는 방법이 고안되어 있다.
하나의 실험 하에서 수행된 모든 expression profile들은 모두 그 실험의
고유한 목표 아래, 고유한 실험 환경에 따른 expression의 uniqueness를 가지고 있고,
따라서 gene expression profile의 유사성을 찾기 위해서는 각 sample들 간의
similarity 보다는 실험 단위의 level에서의 유사성을 찾는 것이 더 의미있지
않을까 했던 것이 내 생각이었다.
이것이 더 의미있다는 것을 보일 수 있다면 또 하나의 좋은 논문 거리가 될 것 같다.
Gene expression 정보가 Public database인 GEO와 ArrayExpress에
축적되는 양이 점점 많아지면서, DB에 들어있는 expression 정보에의
접근이 중요한 Research topic으로 떠오르고 있다.
Sequence alignment와 마찬가지로, 특정한 Gene expression profile과
비슷한 Profile들을 찾고, 묶어내고 하는 일련의 과정들이 바로 이 topic의
목적이 된다.
Bioinfo2007에 발표한 내 논문에서는 실험 단위의 Gene expression 정보들을
clustering하는 방법을 논의했는데, 여기서는 이 보다 작은 sample 단위의
expression profile을 clustering하는 방법이 고안되어 있다.
하나의 실험 하에서 수행된 모든 expression profile들은 모두 그 실험의
고유한 목표 아래, 고유한 실험 환경에 따른 expression의 uniqueness를 가지고 있고,
따라서 gene expression profile의 유사성을 찾기 위해서는 각 sample들 간의
similarity 보다는 실험 단위의 level에서의 유사성을 찾는 것이 더 의미있지
않을까 했던 것이 내 생각이었다.
이것이 더 의미있다는 것을 보일 수 있다면 또 하나의 좋은 논문 거리가 될 것 같다.
Sunday, November 18, 2007
NetworkAnalyzer
Cytoscape의 Plugin package로서
Network의 다양한 physical topology 들을
한꺼번에 계산해주는 NetworkAnalyzer가 공개되었다.
NetworkAnalyzer 홈페이지: http://med.bioinf.mpi-inf.mpg.de/netanalyzer/index.php
Cytoscape 상에서 실행시키면 아래와 같은 계산 결과 창이 뜬다. 각 Graphic은
다양한 size로 export가 가능하다.

Network의 다양한 physical topology 들을
한꺼번에 계산해주는 NetworkAnalyzer가 공개되었다.
NetworkAnalyzer 홈페이지: http://med.bioinf.mpi-inf.mpg.de/netanalyzer/index.php
Cytoscape 상에서 실행시키면 아래와 같은 계산 결과 창이 뜬다. 각 Graphic은
다양한 size로 export가 가능하다.
Monday, November 12, 2007
BioLinux course
URL : http://genome.ku.dk/courses/biolinux/
University of cofenhagen에서 개설된 course로
Bioinformatics 연구 시, OS로 널리 쓰이는 Linux
의 이용과 다양한 bioinformatics approache 이용을
목표로 함.
University of cofenhagen에서 개설된 course로
Bioinformatics 연구 시, OS로 널리 쓰이는 Linux
의 이용과 다양한 bioinformatics approache 이용을
목표로 함.
Subscribe to:
Posts (Atom)